|
OpenCV
4.1.1-pre
Open Source Computer Vision
|


|
|
OpenCV
4.1.1-pre
Open Source Computer Vision
|
|
The functions in this section use a so-called pinhole camera model. More...

|
Modules | |
| Fisheye camera model | |
Definitions: Let P be a point in 3D of coordinates X in the world reference frame (stored in the matrix X) The coordinate vector of P in the camera reference frame is: | |
| C API | |
Classes | |
| struct | cv::CirclesGridFinderParameters |
| class | cv::LMSolver |
| Levenberg-Marquardt solver. More... | |
| class | cv::StereoBM |
| Class for computing stereo correspondence using the block matching algorithm, introduced and contributed to OpenCV by K. More... | |
| class | cv::StereoMatcher |
| The base class for stereo correspondence algorithms. More... | |
| class | cv::StereoSGBM |
| The class implements the modified H. More... | |
Typedefs | |
| typedef CirclesGridFinderParameters | cv::CirclesGridFinderParameters2 |
Functions | |
| double | cv::calibrateCamera (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size imageSize, InputOutputArray cameraMatrix, InputOutputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, OutputArray stdDeviationsIntrinsics, OutputArray stdDeviationsExtrinsics, OutputArray perViewErrors, int flags=0, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON)) |
| Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern. More... | |
| double | cv::calibrateCamera (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size imageSize, InputOutputArray cameraMatrix, InputOutputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, int flags=0, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON)) |
| double | cv::calibrateCameraRO (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size imageSize, int iFixedPoint, InputOutputArray cameraMatrix, InputOutputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, OutputArray newObjPoints, OutputArray stdDeviationsIntrinsics, OutputArray stdDeviationsExtrinsics, OutputArray stdDeviationsObjPoints, OutputArray perViewErrors, int flags=0, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON)) |
| Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern. More... | |
| double | cv::calibrateCameraRO (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size imageSize, int iFixedPoint, InputOutputArray cameraMatrix, InputOutputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, OutputArray newObjPoints, int flags=0, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON)) |
| void | cv::calibrateHandEye (InputArrayOfArrays R_gripper2base, InputArrayOfArrays t_gripper2base, InputArrayOfArrays R_target2cam, InputArrayOfArrays t_target2cam, OutputArray R_cam2gripper, OutputArray t_cam2gripper, HandEyeCalibrationMethod method=CALIB_HAND_EYE_TSAI) |
| Computes Hand-Eye calibration: \(_{}^{g}\textrm{T}_c\). More... | |
| void | cv::calibrationMatrixValues (InputArray cameraMatrix, Size imageSize, double apertureWidth, double apertureHeight, double &fovx, double &fovy, double &focalLength, Point2d &principalPoint, double &aspectRatio) |
| Computes useful camera characteristics from the camera matrix. More... | |
| bool | cv::checkChessboard (InputArray img, Size size) |
| void | cv::composeRT (InputArray rvec1, InputArray tvec1, InputArray rvec2, InputArray tvec2, OutputArray rvec3, OutputArray tvec3, OutputArray dr3dr1=noArray(), OutputArray dr3dt1=noArray(), OutputArray dr3dr2=noArray(), OutputArray dr3dt2=noArray(), OutputArray dt3dr1=noArray(), OutputArray dt3dt1=noArray(), OutputArray dt3dr2=noArray(), OutputArray dt3dt2=noArray()) |
| Combines two rotation-and-shift transformations. More... | |
| void | cv::computeCorrespondEpilines (InputArray points, int whichImage, InputArray F, OutputArray lines) |
| For points in an image of a stereo pair, computes the corresponding epilines in the other image. More... | |
| void | cv::convertPointsFromHomogeneous (InputArray src, OutputArray dst) |
| Converts points from homogeneous to Euclidean space. More... | |
| void | cv::convertPointsHomogeneous (InputArray src, OutputArray dst) |
| Converts points to/from homogeneous coordinates. More... | |
| void | cv::convertPointsToHomogeneous (InputArray src, OutputArray dst) |
| Converts points from Euclidean to homogeneous space. More... | |
| void | cv::correctMatches (InputArray F, InputArray points1, InputArray points2, OutputArray newPoints1, OutputArray newPoints2) |
| Refines coordinates of corresponding points. More... | |
| void | cv::decomposeEssentialMat (InputArray E, OutputArray R1, OutputArray R2, OutputArray t) |
| Decompose an essential matrix to possible rotations and translation. More... | |
| int | cv::decomposeHomographyMat (InputArray H, InputArray K, OutputArrayOfArrays rotations, OutputArrayOfArrays translations, OutputArrayOfArrays normals) |
| Decompose a homography matrix to rotation(s), translation(s) and plane normal(s). More... | |
| void | cv::decomposeProjectionMatrix (InputArray projMatrix, OutputArray cameraMatrix, OutputArray rotMatrix, OutputArray transVect, OutputArray rotMatrixX=noArray(), OutputArray rotMatrixY=noArray(), OutputArray rotMatrixZ=noArray(), OutputArray eulerAngles=noArray()) |
| Decomposes a projection matrix into a rotation matrix and a camera matrix. More... | |
| void | cv::drawChessboardCorners (InputOutputArray image, Size patternSize, InputArray corners, bool patternWasFound) |
| Renders the detected chessboard corners. More... | |
| void | cv::drawFrameAxes (InputOutputArray image, InputArray cameraMatrix, InputArray distCoeffs, InputArray rvec, InputArray tvec, float length, int thickness=3) |
| Draw axes of the world/object coordinate system from pose estimation. More... | |
| cv::Mat | cv::estimateAffine2D (InputArray from, InputArray to, OutputArray inliers=noArray(), int method=RANSAC, double ransacReprojThreshold=3, size_t maxIters=2000, double confidence=0.99, size_t refineIters=10) |
| Computes an optimal affine transformation between two 2D point sets. More... | |
| int | cv::estimateAffine3D (InputArray src, InputArray dst, OutputArray out, OutputArray inliers, double ransacThreshold=3, double confidence=0.99) |
| Computes an optimal affine transformation between two 3D point sets. More... | |
| cv::Mat | cv::estimateAffinePartial2D (InputArray from, InputArray to, OutputArray inliers=noArray(), int method=RANSAC, double ransacReprojThreshold=3, size_t maxIters=2000, double confidence=0.99, size_t refineIters=10) |
| Computes an optimal limited affine transformation with 4 degrees of freedom between two 2D point sets. More... | |
| void | cv::filterHomographyDecompByVisibleRefpoints (InputArrayOfArrays rotations, InputArrayOfArrays normals, InputArray beforePoints, InputArray afterPoints, OutputArray possibleSolutions, InputArray pointsMask=noArray()) |
| Filters homography decompositions based on additional information. More... | |
| void | cv::filterSpeckles (InputOutputArray img, double newVal, int maxSpeckleSize, double maxDiff, InputOutputArray buf=noArray()) |
| Filters off small noise blobs (speckles) in the disparity map. More... | |
| bool | cv::find4QuadCornerSubpix (InputArray img, InputOutputArray corners, Size region_size) |
| finds subpixel-accurate positions of the chessboard corners More... | |
| bool | cv::findChessboardCorners (InputArray image, Size patternSize, OutputArray corners, int flags=CALIB_CB_ADAPTIVE_THRESH+CALIB_CB_NORMALIZE_IMAGE) |
| Finds the positions of internal corners of the chessboard. More... | |
| bool | cv::findChessboardCornersSB (InputArray image, Size patternSize, OutputArray corners, int flags=0) |
| Finds the positions of internal corners of the chessboard using a sector based approach. More... | |
| bool | cv::findCirclesGrid (InputArray image, Size patternSize, OutputArray centers, int flags, const Ptr< FeatureDetector > &blobDetector, const CirclesGridFinderParameters ¶meters) |
| Finds centers in the grid of circles. More... | |
| bool | cv::findCirclesGrid (InputArray image, Size patternSize, OutputArray centers, int flags=CALIB_CB_SYMMETRIC_GRID, const Ptr< FeatureDetector > &blobDetector=SimpleBlobDetector::create()) |
| Mat | cv::findEssentialMat (InputArray points1, InputArray points2, InputArray cameraMatrix, int method=RANSAC, double prob=0.999, double threshold=1.0, OutputArray mask=noArray()) |
| Calculates an essential matrix from the corresponding points in two images. More... | |
| Mat | cv::findEssentialMat (InputArray points1, InputArray points2, double focal=1.0, Point2d pp=Point2d(0, 0), int method=RANSAC, double prob=0.999, double threshold=1.0, OutputArray mask=noArray()) |
| This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts. More... | |
| Mat | cv::findFundamentalMat (InputArray points1, InputArray points2, int method=FM_RANSAC, double ransacReprojThreshold=3., double confidence=0.99, OutputArray mask=noArray()) |
| Calculates a fundamental matrix from the corresponding points in two images. More... | |
| Mat | cv::findFundamentalMat (InputArray points1, InputArray points2, OutputArray mask, int method=FM_RANSAC, double ransacReprojThreshold=3., double confidence=0.99) |
| Mat | cv::findHomography (InputArray srcPoints, InputArray dstPoints, int method=0, double ransacReprojThreshold=3, OutputArray mask=noArray(), const int maxIters=2000, const double confidence=0.995) |
| Finds a perspective transformation between two planes. More... | |
| Mat | cv::findHomography (InputArray srcPoints, InputArray dstPoints, OutputArray mask, int method=0, double ransacReprojThreshold=3) |
| Mat | cv::getDefaultNewCameraMatrix (InputArray cameraMatrix, Size imgsize=Size(), bool centerPrincipalPoint=false) |
| Returns the default new camera matrix. More... | |
| Mat | cv::getOptimalNewCameraMatrix (InputArray cameraMatrix, InputArray distCoeffs, Size imageSize, double alpha, Size newImgSize=Size(), Rect *validPixROI=0, bool centerPrincipalPoint=false) |
| Returns the new camera matrix based on the free scaling parameter. More... | |
| Rect | cv::getValidDisparityROI (Rect roi1, Rect roi2, int minDisparity, int numberOfDisparities, int SADWindowSize) |
| computes valid disparity ROI from the valid ROIs of the rectified images (that are returned by cv::stereoRectify()) More... | |
| Mat | cv::initCameraMatrix2D (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints, Size imageSize, double aspectRatio=1.0) |
| Finds an initial camera matrix from 3D-2D point correspondences. More... | |
| void | cv::initUndistortRectifyMap (InputArray cameraMatrix, InputArray distCoeffs, InputArray R, InputArray newCameraMatrix, Size size, int m1type, OutputArray map1, OutputArray map2) |
| Computes the undistortion and rectification transformation map. More... | |
| float | cv::initWideAngleProjMap (InputArray cameraMatrix, InputArray distCoeffs, Size imageSize, int destImageWidth, int m1type, OutputArray map1, OutputArray map2, enum UndistortTypes projType=PROJ_SPHERICAL_EQRECT, double alpha=0) |
| initializes maps for remap for wide-angle More... | |
| static float | cv::initWideAngleProjMap (InputArray cameraMatrix, InputArray distCoeffs, Size imageSize, int destImageWidth, int m1type, OutputArray map1, OutputArray map2, int projType, double alpha=0) |
| void | cv::matMulDeriv (InputArray A, InputArray B, OutputArray dABdA, OutputArray dABdB) |
| Computes partial derivatives of the matrix product for each multiplied matrix. More... | |
| void | cv::projectPoints (InputArray objectPoints, InputArray rvec, InputArray tvec, InputArray cameraMatrix, InputArray distCoeffs, OutputArray imagePoints, OutputArray jacobian=noArray(), double aspectRatio=0) |
| Projects 3D points to an image plane. More... | |
| int | cv::recoverPose (InputArray E, InputArray points1, InputArray points2, InputArray cameraMatrix, OutputArray R, OutputArray t, InputOutputArray mask=noArray()) |
| Recover relative camera rotation and translation from an estimated essential matrix and the corresponding points in two images, using cheirality check. More... | |
| int | cv::recoverPose (InputArray E, InputArray points1, InputArray points2, OutputArray R, OutputArray t, double focal=1.0, Point2d pp=Point2d(0, 0), InputOutputArray mask=noArray()) |
| This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts. More... | |
| int | cv::recoverPose (InputArray E, InputArray points1, InputArray points2, InputArray cameraMatrix, OutputArray R, OutputArray t, double distanceThresh, InputOutputArray mask=noArray(), OutputArray triangulatedPoints=noArray()) |
| This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts. More... | |
| float | cv::rectify3Collinear (InputArray cameraMatrix1, InputArray distCoeffs1, InputArray cameraMatrix2, InputArray distCoeffs2, InputArray cameraMatrix3, InputArray distCoeffs3, InputArrayOfArrays imgpt1, InputArrayOfArrays imgpt3, Size imageSize, InputArray R12, InputArray T12, InputArray R13, InputArray T13, OutputArray R1, OutputArray R2, OutputArray R3, OutputArray P1, OutputArray P2, OutputArray P3, OutputArray Q, double alpha, Size newImgSize, Rect *roi1, Rect *roi2, int flags) |
| computes the rectification transformations for 3-head camera, where all the heads are on the same line. More... | |
| void | cv::reprojectImageTo3D (InputArray disparity, OutputArray _3dImage, InputArray Q, bool handleMissingValues=false, int ddepth=-1) |
| Reprojects a disparity image to 3D space. More... | |
| void | cv::Rodrigues (InputArray src, OutputArray dst, OutputArray jacobian=noArray()) |
| Converts a rotation matrix to a rotation vector or vice versa. More... | |
| Vec3d | cv::RQDecomp3x3 (InputArray src, OutputArray mtxR, OutputArray mtxQ, OutputArray Qx=noArray(), OutputArray Qy=noArray(), OutputArray Qz=noArray()) |
| Computes an RQ decomposition of 3x3 matrices. More... | |
| double | cv::sampsonDistance (InputArray pt1, InputArray pt2, InputArray F) |
| Calculates the Sampson Distance between two points. More... | |
| int | cv::solveP3P (InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, int flags) |
| Finds an object pose from 3 3D-2D point correspondences. More... | |
| bool | cv::solvePnP (InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess=false, int flags=SOLVEPNP_ITERATIVE) |
| Finds an object pose from 3D-2D point correspondences. More... | |
| int | cv::solvePnPGeneric (InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs, bool useExtrinsicGuess=false, SolvePnPMethod flags=SOLVEPNP_ITERATIVE, InputArray rvec=noArray(), InputArray tvec=noArray(), OutputArray reprojectionError=noArray()) |
| Finds an object pose from 3D-2D point correspondences. More... | |
| bool | cv::solvePnPRansac (InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess=false, int iterationsCount=100, float reprojectionError=8.0, double confidence=0.99, OutputArray inliers=noArray(), int flags=SOLVEPNP_ITERATIVE) |
| Finds an object pose from 3D-2D point correspondences using the RANSAC scheme. More... | |
| void | cv::solvePnPRefineLM (InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, InputOutputArray rvec, InputOutputArray tvec, TermCriteria criteria=TermCriteria(TermCriteria::EPS+TermCriteria::COUNT, 20, FLT_EPSILON)) |
| Refine a pose (the translation and the rotation that transform a 3D point expressed in the object coordinate frame to the camera coordinate frame) from a 3D-2D point correspondences and starting from an initial solution. More... | |
| void | cv::solvePnPRefineVVS (InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, InputOutputArray rvec, InputOutputArray tvec, TermCriteria criteria=TermCriteria(TermCriteria::EPS+TermCriteria::COUNT, 20, FLT_EPSILON), double VVSlambda=1) |
| Refine a pose (the translation and the rotation that transform a 3D point expressed in the object coordinate frame to the camera coordinate frame) from a 3D-2D point correspondences and starting from an initial solution. More... | |
| double | cv::stereoCalibrate (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints1, InputArrayOfArrays imagePoints2, InputOutputArray cameraMatrix1, InputOutputArray distCoeffs1, InputOutputArray cameraMatrix2, InputOutputArray distCoeffs2, Size imageSize, InputOutputArray R, InputOutputArray T, OutputArray E, OutputArray F, OutputArray perViewErrors, int flags=CALIB_FIX_INTRINSIC, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, 1e-6)) |
| Calibrates the stereo camera. More... | |
| double | cv::stereoCalibrate (InputArrayOfArrays objectPoints, InputArrayOfArrays imagePoints1, InputArrayOfArrays imagePoints2, InputOutputArray cameraMatrix1, InputOutputArray distCoeffs1, InputOutputArray cameraMatrix2, InputOutputArray distCoeffs2, Size imageSize, OutputArray R, OutputArray T, OutputArray E, OutputArray F, int flags=CALIB_FIX_INTRINSIC, TermCriteria criteria=TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, 1e-6)) |
| void | cv::stereoRectify (InputArray cameraMatrix1, InputArray distCoeffs1, InputArray cameraMatrix2, InputArray distCoeffs2, Size imageSize, InputArray R, InputArray T, OutputArray R1, OutputArray R2, OutputArray P1, OutputArray P2, OutputArray Q, int flags=CALIB_ZERO_DISPARITY, double alpha=-1, Size newImageSize=Size(), Rect *validPixROI1=0, Rect *validPixROI2=0) |
| Computes rectification transforms for each head of a calibrated stereo camera. More... | |
| bool | cv::stereoRectifyUncalibrated (InputArray points1, InputArray points2, InputArray F, Size imgSize, OutputArray H1, OutputArray H2, double threshold=5) |
| Computes a rectification transform for an uncalibrated stereo camera. More... | |
| void | cv::triangulatePoints (InputArray projMatr1, InputArray projMatr2, InputArray projPoints1, InputArray projPoints2, OutputArray points4D) |
| Reconstructs points by triangulation. More... | |
| void | cv::undistort (InputArray src, OutputArray dst, InputArray cameraMatrix, InputArray distCoeffs, InputArray newCameraMatrix=noArray()) |
| Transforms an image to compensate for lens distortion. More... | |
| void | cv::undistortPoints (InputArray src, OutputArray dst, InputArray cameraMatrix, InputArray distCoeffs, InputArray R=noArray(), InputArray P=noArray()) |
| Computes the ideal point coordinates from the observed point coordinates. More... | |
| void | cv::undistortPoints (InputArray src, OutputArray dst, InputArray cameraMatrix, InputArray distCoeffs, InputArray R, InputArray P, TermCriteria criteria) |
| This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts. More... | |
| void | cv::validateDisparity (InputOutputArray disparity, InputArray cost, int minDisparity, int numberOfDisparities, int disp12MaxDisp=1) |
| validates disparity using the left-right check. The matrix "cost" should be computed by the stereo correspondence algorithm More... | |
The functions in this section use a so-called pinhole camera model.
In this model, a scene view is formed by projecting 3D points into the image plane using a perspective transformation.
\[s \; m' = A [R|t] M'\]
or
\[s \vecthree{u}{v}{1} = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1} \begin{bmatrix} r_{11} & r_{12} & r_{13} & t_1 \\ r_{21} & r_{22} & r_{23} & t_2 \\ r_{31} & r_{32} & r_{33} & t_3 \end{bmatrix} \begin{bmatrix} X \\ Y \\ Z \\ 1 \end{bmatrix}\]
where:
Thus, if an image from the camera is scaled by a factor, all of these parameters should be scaled (multiplied/divided, respectively) by the same factor. The matrix of intrinsic parameters does not depend on the scene viewed. So, once estimated, it can be re-used as long as the focal length is fixed (in case of zoom lens). The joint rotation-translation matrix \([R|t]\) is called a matrix of extrinsic parameters. It is used to describe the camera motion around a static scene, or vice versa, rigid motion of an object in front of a still camera. That is, \([R|t]\) translates coordinates of a point \((X, Y, Z)\) to a coordinate system, fixed with respect to the camera. The transformation above is equivalent to the following (when \(z \ne 0\) ):
\[\begin{array}{l} \vecthree{x}{y}{z} = R \vecthree{X}{Y}{Z} + t \\ x' = x/z \\ y' = y/z \\ u = f_x*x' + c_x \\ v = f_y*y' + c_y \end{array}\]
The following figure illustrates the pinhole camera model.
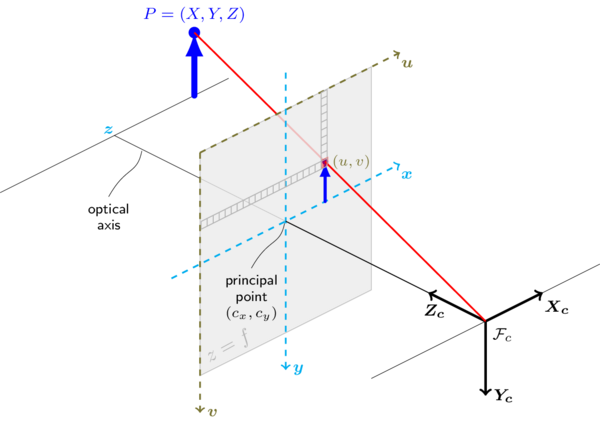
Real lenses usually have some distortion, mostly radial distortion and slight tangential distortion. So, the above model is extended as:
\[\begin{array}{l} \vecthree{x}{y}{z} = R \vecthree{X}{Y}{Z} + t \\ x' = x/z \\ y' = y/z \\ x'' = x' \frac{1 + k_1 r^2 + k_2 r^4 + k_3 r^6}{1 + k_4 r^2 + k_5 r^4 + k_6 r^6} + 2 p_1 x' y' + p_2(r^2 + 2 x'^2) + s_1 r^2 + s_2 r^4 \\ y'' = y' \frac{1 + k_1 r^2 + k_2 r^4 + k_3 r^6}{1 + k_4 r^2 + k_5 r^4 + k_6 r^6} + p_1 (r^2 + 2 y'^2) + 2 p_2 x' y' + s_3 r^2 + s_4 r^4 \\ \text{where} \quad r^2 = x'^2 + y'^2 \\ u = f_x*x'' + c_x \\ v = f_y*y'' + c_y \end{array}\]
\(k_1\), \(k_2\), \(k_3\), \(k_4\), \(k_5\), and \(k_6\) are radial distortion coefficients. \(p_1\) and \(p_2\) are tangential distortion coefficients. \(s_1\), \(s_2\), \(s_3\), and \(s_4\), are the thin prism distortion coefficients. Higher-order coefficients are not considered in OpenCV.
The next figures show two common types of radial distortion: barrel distortion (typically \( k_1 < 0 \)) and pincushion distortion (typically \( k_1 > 0 \)).

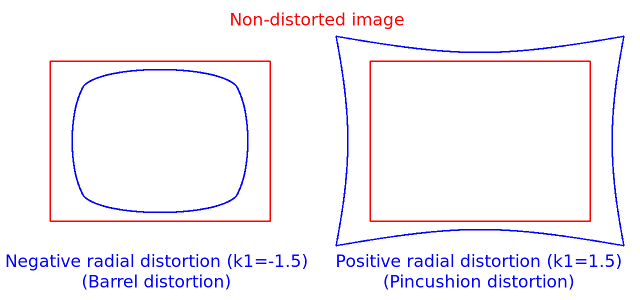
In some cases the image sensor may be tilted in order to focus an oblique plane in front of the camera (Scheimpfug condition). This can be useful for particle image velocimetry (PIV) or triangulation with a laser fan. The tilt causes a perspective distortion of \(x''\) and \(y''\). This distortion can be modelled in the following way, see e.g. [56].
\[\begin{array}{l} s\vecthree{x'''}{y'''}{1} = \vecthreethree{R_{33}(\tau_x, \tau_y)}{0}{-R_{13}(\tau_x, \tau_y)} {0}{R_{33}(\tau_x, \tau_y)}{-R_{23}(\tau_x, \tau_y)} {0}{0}{1} R(\tau_x, \tau_y) \vecthree{x''}{y''}{1}\\ u = f_x*x''' + c_x \\ v = f_y*y''' + c_y \end{array}\]
where the matrix \(R(\tau_x, \tau_y)\) is defined by two rotations with angular parameter \(\tau_x\) and \(\tau_y\), respectively,
\[ R(\tau_x, \tau_y) = \vecthreethree{\cos(\tau_y)}{0}{-\sin(\tau_y)}{0}{1}{0}{\sin(\tau_y)}{0}{\cos(\tau_y)} \vecthreethree{1}{0}{0}{0}{\cos(\tau_x)}{\sin(\tau_x)}{0}{-\sin(\tau_x)}{\cos(\tau_x)} = \vecthreethree{\cos(\tau_y)}{\sin(\tau_y)\sin(\tau_x)}{-\sin(\tau_y)\cos(\tau_x)} {0}{\cos(\tau_x)}{\sin(\tau_x)} {\sin(\tau_y)}{-\cos(\tau_y)\sin(\tau_x)}{\cos(\tau_y)\cos(\tau_x)}. \]
In the functions below the coefficients are passed or returned as
\[(k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\]
vector. That is, if the vector contains four elements, it means that \(k_3=0\) . The distortion coefficients do not depend on the scene viewed. Thus, they also belong to the intrinsic camera parameters. And they remain the same regardless of the captured image resolution. If, for example, a camera has been calibrated on images of 320 x 240 resolution, absolutely the same distortion coefficients can be used for 640 x 480 images from the same camera while \(f_x\), \(f_y\), \(c_x\), and \(c_y\) need to be scaled appropriately.
The functions below use the above model to do the following:
#include <opencv2/calib3d.hpp>
| anonymous enum |
| anonymous enum |
| anonymous enum |
| anonymous enum |
#include <opencv2/calib3d.hpp>
| Enumerator | |
|---|---|
| CALIB_NINTRINSIC | |
| CALIB_USE_INTRINSIC_GUESS | |
| CALIB_FIX_ASPECT_RATIO | |
| CALIB_FIX_PRINCIPAL_POINT | |
| CALIB_ZERO_TANGENT_DIST | |
| CALIB_FIX_FOCAL_LENGTH | |
| CALIB_FIX_K1 | |
| CALIB_FIX_K2 | |
| CALIB_FIX_K3 | |
| CALIB_FIX_K4 | |
| CALIB_FIX_K5 | |
| CALIB_FIX_K6 | |
| CALIB_RATIONAL_MODEL | |
| CALIB_THIN_PRISM_MODEL | |
| CALIB_FIX_S1_S2_S3_S4 | |
| CALIB_TILTED_MODEL | |
| CALIB_FIX_TAUX_TAUY | |
| CALIB_USE_QR | use QR instead of SVD decomposition for solving. Faster but potentially less precise |
| CALIB_FIX_TANGENT_DIST | |
| CALIB_FIX_INTRINSIC | |
| CALIB_SAME_FOCAL_LENGTH | |
| CALIB_ZERO_DISPARITY | |
| CALIB_USE_LU | use LU instead of SVD decomposition for solving. much faster but potentially less precise |
| CALIB_USE_EXTRINSIC_GUESS | for stereoCalibrate |
| anonymous enum |
#include <opencv2/calib3d.hpp>
| Enumerator | |
|---|---|
| CALIB_HAND_EYE_TSAI | A New Technique for Fully Autonomous and Efficient 3D Robotics Hand/Eye Calibration [95]. |
| CALIB_HAND_EYE_PARK | Robot Sensor Calibration: Solving AX = XB on the Euclidean Group [73]. |
| CALIB_HAND_EYE_HORAUD | Hand-eye Calibration [44]. |
| CALIB_HAND_EYE_ANDREFF | On-line Hand-Eye Calibration [3]. |
| CALIB_HAND_EYE_DANIILIDIS | Hand-Eye Calibration Using Dual Quaternions [23]. |
| enum cv::SolvePnPMethod |
#include <opencv2/calib3d.hpp>
| Enumerator | |
|---|---|
| SOLVEPNP_ITERATIVE | |
| SOLVEPNP_EPNP | EPnP: Efficient Perspective-n-Point Camera Pose Estimation [52]. |
| SOLVEPNP_P3P | Complete Solution Classification for the Perspective-Three-Point Problem [36]. |
| SOLVEPNP_DLS | A Direct Least-Squares (DLS) Method for PnP [42]. |
| SOLVEPNP_UPNP | Exhaustive Linearization for Robust Camera Pose and Focal Length Estimation [74]. |
| SOLVEPNP_AP3P | An Efficient Algebraic Solution to the Perspective-Three-Point Problem [47]. |
| SOLVEPNP_IPPE | Infinitesimal Plane-Based Pose Estimation [21] |
| SOLVEPNP_IPPE_SQUARE | Infinitesimal Plane-Based Pose Estimation [21]
|
| enum cv::UndistortTypes |
#include <opencv2/calib3d.hpp>
cv::undistort mode
| Enumerator | |
|---|---|
| PROJ_SPHERICAL_ORTHO | |
| PROJ_SPHERICAL_EQRECT | |
| double cv::calibrateCamera | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints, | ||
| Size | imageSize, | ||
| InputOutputArray | cameraMatrix, | ||
| InputOutputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| OutputArray | stdDeviationsIntrinsics, | ||
| OutputArray | stdDeviationsExtrinsics, | ||
| OutputArray | perViewErrors, | ||
| int | flags = 0, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON) |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern.
| objectPoints | In the new interface it is a vector of vectors of calibration pattern points in the calibration pattern coordinate space (e.g. std::vector<std::vector<cv::Vec3f>>). The outer vector contains as many elements as the number of the pattern views. If the same calibration pattern is shown in each view and it is fully visible, all the vectors will be the same. Although, it is possible to use partially occluded patterns, or even different patterns in different views. Then, the vectors will be different. The points are 3D, but since they are in a pattern coordinate system, then, if the rig is planar, it may make sense to put the model to a XY coordinate plane so that Z-coordinate of each input object point is 0. In the old interface all the vectors of object points from different views are concatenated together. |
| imagePoints | In the new interface it is a vector of vectors of the projections of calibration pattern points (e.g. std::vector<std::vector<cv::Vec2f>>). imagePoints.size() and objectPoints.size() and imagePoints[i].size() must be equal to objectPoints[i].size() for each i. In the old interface all the vectors of object points from different views are concatenated together. |
| imageSize | Size of the image used only to initialize the intrinsic camera matrix. |
| cameraMatrix | Output 3x3 floating-point camera matrix \(A = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . If CV_CALIB_USE_INTRINSIC_GUESS and/or CALIB_FIX_ASPECT_RATIO are specified, some or all of fx, fy, cx, cy must be initialized before calling the function. |
| distCoeffs | Output vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. |
| rvecs | Output vector of rotation vectors (see Rodrigues ) estimated for each pattern view (e.g. std::vector<cv::Mat>>). That is, each k-th rotation vector together with the corresponding k-th translation vector (see the next output parameter description) brings the calibration pattern from the model coordinate space (in which object points are specified) to the world coordinate space, that is, a real position of the calibration pattern in the k-th pattern view (k=0.. M -1). |
| tvecs | Output vector of translation vectors estimated for each pattern view. |
| stdDeviationsIntrinsics | Output vector of standard deviations estimated for intrinsic parameters. Order of deviations values: \((f_x, f_y, c_x, c_y, k_1, k_2, p_1, p_2, k_3, k_4, k_5, k_6 , s_1, s_2, s_3, s_4, \tau_x, \tau_y)\) If one of parameters is not estimated, it's deviation is equals to zero. |
| stdDeviationsExtrinsics | Output vector of standard deviations estimated for extrinsic parameters. Order of deviations values: \((R_1, T_1, \dotsc , R_M, T_M)\) where M is number of pattern views, \(R_i, T_i\) are concatenated 1x3 vectors. |
| perViewErrors | Output vector of the RMS re-projection error estimated for each pattern view. |
| flags | Different flags that may be zero or a combination of the following values:
|
| criteria | Termination criteria for the iterative optimization algorithm. |
The function estimates the intrinsic camera parameters and extrinsic parameters for each of the views. The algorithm is based on [108] and [11] . The coordinates of 3D object points and their corresponding 2D projections in each view must be specified. That may be achieved by using an object with a known geometry and easily detectable feature points. Such an object is called a calibration rig or calibration pattern, and OpenCV has built-in support for a chessboard as a calibration rig (see findChessboardCorners ). Currently, initialization of intrinsic parameters (when CALIB_USE_INTRINSIC_GUESS is not set) is only implemented for planar calibration patterns (where Z-coordinates of the object points must be all zeros). 3D calibration rigs can also be used as long as initial cameraMatrix is provided.
The algorithm performs the following steps:
| double cv::calibrateCamera | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints, | ||
| Size | imageSize, | ||
| InputOutputArray | cameraMatrix, | ||
| InputOutputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| int | flags = 0, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON) |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| double cv::calibrateCameraRO | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints, | ||
| Size | imageSize, | ||
| int | iFixedPoint, | ||
| InputOutputArray | cameraMatrix, | ||
| InputOutputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| OutputArray | newObjPoints, | ||
| OutputArray | stdDeviationsIntrinsics, | ||
| OutputArray | stdDeviationsExtrinsics, | ||
| OutputArray | stdDeviationsObjPoints, | ||
| OutputArray | perViewErrors, | ||
| int | flags = 0, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON) |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern.
This function is an extension of calibrateCamera() with the method of releasing object which was proposed in [88]. In many common cases with inaccurate, unmeasured, roughly planar targets (calibration plates), this method can dramatically improve the precision of the estimated camera parameters. Both the object-releasing method and standard method are supported by this function. Use the parameter iFixedPoint for method selection. In the internal implementation, calibrateCamera() is a wrapper for this function.
| objectPoints | Vector of vectors of calibration pattern points in the calibration pattern coordinate space. See calibrateCamera() for details. If the method of releasing object to be used, the identical calibration board must be used in each view and it must be fully visible, and all objectPoints[i] must be the same and all points should be roughly close to a plane. The calibration target has to be rigid, or at least static if the camera (rather than the calibration target) is shifted for grabbing images. |
| imagePoints | Vector of vectors of the projections of calibration pattern points. See calibrateCamera() for details. |
| imageSize | Size of the image used only to initialize the intrinsic camera matrix. |
| iFixedPoint | The index of the 3D object point in objectPoints[0] to be fixed. It also acts as a switch for calibration method selection. If object-releasing method to be used, pass in the parameter in the range of [1, objectPoints[0].size()-2], otherwise a value out of this range will make standard calibration method selected. Usually the top-right corner point of the calibration board grid is recommended to be fixed when object-releasing method being utilized. According to [88], two other points are also fixed. In this implementation, objectPoints[0].front and objectPoints[0].back.z are used. With object-releasing method, accurate rvecs, tvecs and newObjPoints are only possible if coordinates of these three fixed points are accurate enough. |
| cameraMatrix | Output 3x3 floating-point camera matrix. See calibrateCamera() for details. |
| distCoeffs | Output vector of distortion coefficients. See calibrateCamera() for details. |
| rvecs | Output vector of rotation vectors estimated for each pattern view. See calibrateCamera() for details. |
| tvecs | Output vector of translation vectors estimated for each pattern view. |
| newObjPoints | The updated output vector of calibration pattern points. The coordinates might be scaled based on three fixed points. The returned coordinates are accurate only if the above mentioned three fixed points are accurate. If not needed, noArray() can be passed in. This parameter is ignored with standard calibration method. |
| stdDeviationsIntrinsics | Output vector of standard deviations estimated for intrinsic parameters. See calibrateCamera() for details. |
| stdDeviationsExtrinsics | Output vector of standard deviations estimated for extrinsic parameters. See calibrateCamera() for details. |
| stdDeviationsObjPoints | Output vector of standard deviations estimated for refined coordinates of calibration pattern points. It has the same size and order as objectPoints[0] vector. This parameter is ignored with standard calibration method. |
| perViewErrors | Output vector of the RMS re-projection error estimated for each pattern view. |
| flags | Different flags that may be zero or a combination of some predefined values. See calibrateCamera() for details. If the method of releasing object is used, the calibration time may be much longer. CALIB_USE_QR or CALIB_USE_LU could be used for faster calibration with potentially less precise and less stable in some rare cases. |
| criteria | Termination criteria for the iterative optimization algorithm. |
The function estimates the intrinsic camera parameters and extrinsic parameters for each of the views. The algorithm is based on [108], [11] and [88]. See calibrateCamera() for other detailed explanations.
| double cv::calibrateCameraRO | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints, | ||
| Size | imageSize, | ||
| int | iFixedPoint, | ||
| InputOutputArray | cameraMatrix, | ||
| InputOutputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| OutputArray | newObjPoints, | ||
| int | flags = 0, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON) |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| void cv::calibrateHandEye | ( | InputArrayOfArrays | R_gripper2base, |
| InputArrayOfArrays | t_gripper2base, | ||
| InputArrayOfArrays | R_target2cam, | ||
| InputArrayOfArrays | t_target2cam, | ||
| OutputArray | R_cam2gripper, | ||
| OutputArray | t_cam2gripper, | ||
| HandEyeCalibrationMethod | method = CALIB_HAND_EYE_TSAI |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes Hand-Eye calibration: \(_{}^{g}\textrm{T}_c\).
| [in] | R_gripper2base | Rotation part extracted from the homogeneous matrix that transforms a point expressed in the gripper frame to the robot base frame ( \(_{}^{b}\textrm{T}_g\)). This is a vector (vector<Mat>) that contains the rotation matrices for all the transformations from gripper frame to robot base frame. |
| [in] | t_gripper2base | Translation part extracted from the homogeneous matrix that transforms a point expressed in the gripper frame to the robot base frame ( \(_{}^{b}\textrm{T}_g\)). This is a vector (vector<Mat>) that contains the translation vectors for all the transformations from gripper frame to robot base frame. |
| [in] | R_target2cam | Rotation part extracted from the homogeneous matrix that transforms a point expressed in the target frame to the camera frame ( \(_{}^{c}\textrm{T}_t\)). This is a vector (vector<Mat>) that contains the rotation matrices for all the transformations from calibration target frame to camera frame. |
| [in] | t_target2cam | Rotation part extracted from the homogeneous matrix that transforms a point expressed in the target frame to the camera frame ( \(_{}^{c}\textrm{T}_t\)). This is a vector (vector<Mat>) that contains the translation vectors for all the transformations from calibration target frame to camera frame. |
| [out] | R_cam2gripper | Estimated rotation part extracted from the homogeneous matrix that transforms a point expressed in the camera frame to the gripper frame ( \(_{}^{g}\textrm{T}_c\)). |
| [out] | t_cam2gripper | Estimated translation part extracted from the homogeneous matrix that transforms a point expressed in the camera frame to the gripper frame ( \(_{}^{g}\textrm{T}_c\)). |
| [in] | method | One of the implemented Hand-Eye calibration method, see cv::HandEyeCalibrationMethod |
The function performs the Hand-Eye calibration using various methods. One approach consists in estimating the rotation then the translation (separable solutions) and the following methods are implemented:
Another approach consists in estimating simultaneously the rotation and the translation (simultaneous solutions), with the following implemented method:
The following picture describes the Hand-Eye calibration problem where the transformation between a camera ("eye") mounted on a robot gripper ("hand") has to be estimated.
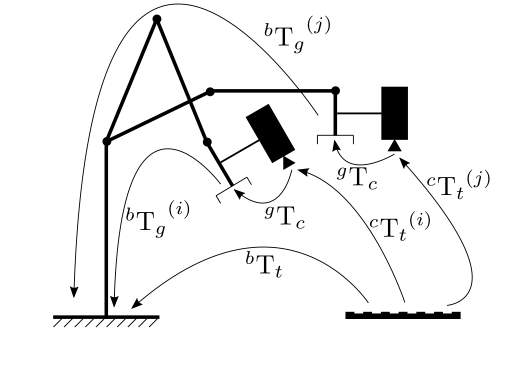
The calibration procedure is the following:
\[ \begin{bmatrix} X_b\\ Y_b\\ Z_b\\ 1 \end{bmatrix} = \begin{bmatrix} _{}^{b}\textrm{R}_g & _{}^{b}\textrm{t}_g \\ 0_{1 \times 3} & 1 \end{bmatrix} \begin{bmatrix} X_g\\ Y_g\\ Z_g\\ 1 \end{bmatrix} \]
\[ \begin{bmatrix} X_c\\ Y_c\\ Z_c\\ 1 \end{bmatrix} = \begin{bmatrix} _{}^{c}\textrm{R}_t & _{}^{c}\textrm{t}_t \\ 0_{1 \times 3} & 1 \end{bmatrix} \begin{bmatrix} X_t\\ Y_t\\ Z_t\\ 1 \end{bmatrix} \]
The Hand-Eye calibration procedure returns the following homogeneous transformation
\[ \begin{bmatrix} X_g\\ Y_g\\ Z_g\\ 1 \end{bmatrix} = \begin{bmatrix} _{}^{g}\textrm{R}_c & _{}^{g}\textrm{t}_c \\ 0_{1 \times 3} & 1 \end{bmatrix} \begin{bmatrix} X_c\\ Y_c\\ Z_c\\ 1 \end{bmatrix} \]
This problem is also known as solving the \(\mathbf{A}\mathbf{X}=\mathbf{X}\mathbf{B}\) equation:
\[ \begin{align*} ^{b}{\textrm{T}_g}^{(1)} \hspace{0.2em} ^{g}\textrm{T}_c \hspace{0.2em} ^{c}{\textrm{T}_t}^{(1)} &= \hspace{0.1em} ^{b}{\textrm{T}_g}^{(2)} \hspace{0.2em} ^{g}\textrm{T}_c \hspace{0.2em} ^{c}{\textrm{T}_t}^{(2)} \\ (^{b}{\textrm{T}_g}^{(2)})^{-1} \hspace{0.2em} ^{b}{\textrm{T}_g}^{(1)} \hspace{0.2em} ^{g}\textrm{T}_c &= \hspace{0.1em} ^{g}\textrm{T}_c \hspace{0.2em} ^{c}{\textrm{T}_t}^{(2)} (^{c}{\textrm{T}_t}^{(1)})^{-1} \\ \textrm{A}_i \textrm{X} &= \textrm{X} \textrm{B}_i \\ \end{align*} \]
| void cv::calibrationMatrixValues | ( | InputArray | cameraMatrix, |
| Size | imageSize, | ||
| double | apertureWidth, | ||
| double | apertureHeight, | ||
| double & | fovx, | ||
| double & | fovy, | ||
| double & | focalLength, | ||
| Point2d & | principalPoint, | ||
| double & | aspectRatio | ||
| ) |
#include <opencv2/calib3d.hpp>
Computes useful camera characteristics from the camera matrix.
| cameraMatrix | Input camera matrix that can be estimated by calibrateCamera or stereoCalibrate . |
| imageSize | Input image size in pixels. |
| apertureWidth | Physical width in mm of the sensor. |
| apertureHeight | Physical height in mm of the sensor. |
| fovx | Output field of view in degrees along the horizontal sensor axis. |
| fovy | Output field of view in degrees along the vertical sensor axis. |
| focalLength | Focal length of the lens in mm. |
| principalPoint | Principal point in mm. |
| aspectRatio | \(f_y/f_x\) |
The function computes various useful camera characteristics from the previously estimated camera matrix.
| bool cv::checkChessboard | ( | InputArray | img, |
| Size | size | ||
| ) |
#include <opencv2/calib3d.hpp>
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::composeRT | ( | InputArray | rvec1, |
| InputArray | tvec1, | ||
| InputArray | rvec2, | ||
| InputArray | tvec2, | ||
| OutputArray | rvec3, | ||
| OutputArray | tvec3, | ||
| OutputArray | dr3dr1 = noArray(), |
||
| OutputArray | dr3dt1 = noArray(), |
||
| OutputArray | dr3dr2 = noArray(), |
||
| OutputArray | dr3dt2 = noArray(), |
||
| OutputArray | dt3dr1 = noArray(), |
||
| OutputArray | dt3dt1 = noArray(), |
||
| OutputArray | dt3dr2 = noArray(), |
||
| OutputArray | dt3dt2 = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Combines two rotation-and-shift transformations.
| rvec1 | First rotation vector. |
| tvec1 | First translation vector. |
| rvec2 | Second rotation vector. |
| tvec2 | Second translation vector. |
| rvec3 | Output rotation vector of the superposition. |
| tvec3 | Output translation vector of the superposition. |
| dr3dr1 | Optional output derivative of rvec3 with regard to rvec1 |
| dr3dt1 | Optional output derivative of rvec3 with regard to tvec1 |
| dr3dr2 | Optional output derivative of rvec3 with regard to rvec2 |
| dr3dt2 | Optional output derivative of rvec3 with regard to tvec2 |
| dt3dr1 | Optional output derivative of tvec3 with regard to rvec1 |
| dt3dt1 | Optional output derivative of tvec3 with regard to tvec1 |
| dt3dr2 | Optional output derivative of tvec3 with regard to rvec2 |
| dt3dt2 | Optional output derivative of tvec3 with regard to tvec2 |
The functions compute:
\[\begin{array}{l} \texttt{rvec3} = \mathrm{rodrigues} ^{-1} \left ( \mathrm{rodrigues} ( \texttt{rvec2} ) \cdot \mathrm{rodrigues} ( \texttt{rvec1} ) \right ) \\ \texttt{tvec3} = \mathrm{rodrigues} ( \texttt{rvec2} ) \cdot \texttt{tvec1} + \texttt{tvec2} \end{array} ,\]
where \(\mathrm{rodrigues}\) denotes a rotation vector to a rotation matrix transformation, and \(\mathrm{rodrigues}^{-1}\) denotes the inverse transformation. See Rodrigues for details.
Also, the functions can compute the derivatives of the output vectors with regards to the input vectors (see matMulDeriv ). The functions are used inside stereoCalibrate but can also be used in your own code where Levenberg-Marquardt or another gradient-based solver is used to optimize a function that contains a matrix multiplication.
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::computeCorrespondEpilines | ( | InputArray | points, |
| int | whichImage, | ||
| InputArray | F, | ||
| OutputArray | lines | ||
| ) |
#include <opencv2/calib3d.hpp>
For points in an image of a stereo pair, computes the corresponding epilines in the other image.
| points | Input points. \(N \times 1\) or \(1 \times N\) matrix of type CV_32FC2 or vector<Point2f> . |
| whichImage | Index of the image (1 or 2) that contains the points . |
| F | Fundamental matrix that can be estimated using findFundamentalMat or stereoRectify . |
| lines | Output vector of the epipolar lines corresponding to the points in the other image. Each line \(ax + by + c=0\) is encoded by 3 numbers \((a, b, c)\) . |
For every point in one of the two images of a stereo pair, the function finds the equation of the corresponding epipolar line in the other image.
From the fundamental matrix definition (see findFundamentalMat ), line \(l^{(2)}_i\) in the second image for the point \(p^{(1)}_i\) in the first image (when whichImage=1 ) is computed as:
\[l^{(2)}_i = F p^{(1)}_i\]
And vice versa, when whichImage=2, \(l^{(1)}_i\) is computed from \(p^{(2)}_i\) as:
\[l^{(1)}_i = F^T p^{(2)}_i\]
Line coefficients are defined up to a scale. They are normalized so that \(a_i^2+b_i^2=1\) .
| void cv::convertPointsFromHomogeneous | ( | InputArray | src, |
| OutputArray | dst | ||
| ) |
#include <opencv2/calib3d.hpp>
Converts points from homogeneous to Euclidean space.
| src | Input vector of N-dimensional points. |
| dst | Output vector of N-1-dimensional points. |
The function converts points homogeneous to Euclidean space using perspective projection. That is, each point (x1, x2, ... x(n-1), xn) is converted to (x1/xn, x2/xn, ..., x(n-1)/xn). When xn=0, the output point coordinates will be (0,0,0,...).
| void cv::convertPointsHomogeneous | ( | InputArray | src, |
| OutputArray | dst | ||
| ) |
#include <opencv2/calib3d.hpp>
Converts points to/from homogeneous coordinates.
| src | Input array or vector of 2D, 3D, or 4D points. |
| dst | Output vector of 2D, 3D, or 4D points. |
The function converts 2D or 3D points from/to homogeneous coordinates by calling either convertPointsToHomogeneous or convertPointsFromHomogeneous.
| void cv::convertPointsToHomogeneous | ( | InputArray | src, |
| OutputArray | dst | ||
| ) |
#include <opencv2/calib3d.hpp>
Converts points from Euclidean to homogeneous space.
| src | Input vector of N-dimensional points. |
| dst | Output vector of N+1-dimensional points. |
The function converts points from Euclidean to homogeneous space by appending 1's to the tuple of point coordinates. That is, each point (x1, x2, ..., xn) is converted to (x1, x2, ..., xn, 1).
| void cv::correctMatches | ( | InputArray | F, |
| InputArray | points1, | ||
| InputArray | points2, | ||
| OutputArray | newPoints1, | ||
| OutputArray | newPoints2 | ||
| ) |
#include <opencv2/calib3d.hpp>
Refines coordinates of corresponding points.
| F | 3x3 fundamental matrix. |
| points1 | 1xN array containing the first set of points. |
| points2 | 1xN array containing the second set of points. |
| newPoints1 | The optimized points1. |
| newPoints2 | The optimized points2. |
The function implements the Optimal Triangulation Method (see Multiple View Geometry for details). For each given point correspondence points1[i] <-> points2[i], and a fundamental matrix F, it computes the corrected correspondences newPoints1[i] <-> newPoints2[i] that minimize the geometric error \(d(points1[i], newPoints1[i])^2 + d(points2[i],newPoints2[i])^2\) (where \(d(a,b)\) is the geometric distance between points \(a\) and \(b\) ) subject to the epipolar constraint \(newPoints2^T * F * newPoints1 = 0\) .
| void cv::decomposeEssentialMat | ( | InputArray | E, |
| OutputArray | R1, | ||
| OutputArray | R2, | ||
| OutputArray | t | ||
| ) |
#include <opencv2/calib3d.hpp>
Decompose an essential matrix to possible rotations and translation.
| E | The input essential matrix. |
| R1 | One possible rotation matrix. |
| R2 | Another possible rotation matrix. |
| t | One possible translation. |
This function decompose an essential matrix E using svd decomposition [40] . Generally 4 possible poses exists for a given E. They are \([R_1, t]\), \([R_1, -t]\), \([R_2, t]\), \([R_2, -t]\). By decomposing E, you can only get the direction of the translation, so the function returns unit t.
| int cv::decomposeHomographyMat | ( | InputArray | H, |
| InputArray | K, | ||
| OutputArrayOfArrays | rotations, | ||
| OutputArrayOfArrays | translations, | ||
| OutputArrayOfArrays | normals | ||
| ) |
#include <opencv2/calib3d.hpp>
Decompose a homography matrix to rotation(s), translation(s) and plane normal(s).
| H | The input homography matrix between two images. |
| K | The input intrinsic camera calibration matrix. |
| rotations | Array of rotation matrices. |
| translations | Array of translation matrices. |
| normals | Array of plane normal matrices. |
This function extracts relative camera motion between two views observing a planar object from the homography H induced by the plane. The intrinsic camera matrix K must also be provided. The function may return up to four mathematical solution sets. At least two of the solutions may further be invalidated if point correspondences are available by applying positive depth constraint (all points must be in front of the camera). The decomposition method is described in detail in [62] .
| void cv::decomposeProjectionMatrix | ( | InputArray | projMatrix, |
| OutputArray | cameraMatrix, | ||
| OutputArray | rotMatrix, | ||
| OutputArray | transVect, | ||
| OutputArray | rotMatrixX = noArray(), |
||
| OutputArray | rotMatrixY = noArray(), |
||
| OutputArray | rotMatrixZ = noArray(), |
||
| OutputArray | eulerAngles = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Decomposes a projection matrix into a rotation matrix and a camera matrix.
| projMatrix | 3x4 input projection matrix P. |
| cameraMatrix | Output 3x3 camera matrix K. |
| rotMatrix | Output 3x3 external rotation matrix R. |
| transVect | Output 4x1 translation vector T. |
| rotMatrixX | Optional 3x3 rotation matrix around x-axis. |
| rotMatrixY | Optional 3x3 rotation matrix around y-axis. |
| rotMatrixZ | Optional 3x3 rotation matrix around z-axis. |
| eulerAngles | Optional three-element vector containing three Euler angles of rotation in degrees. |
The function computes a decomposition of a projection matrix into a calibration and a rotation matrix and the position of a camera.
It optionally returns three rotation matrices, one for each axis, and three Euler angles that could be used in OpenGL. Note, there is always more than one sequence of rotations about the three principal axes that results in the same orientation of an object, e.g. see [86] . Returned tree rotation matrices and corresponding three Euler angles are only one of the possible solutions.
The function is based on RQDecomp3x3 .
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::drawChessboardCorners | ( | InputOutputArray | image, |
| Size | patternSize, | ||
| InputArray | corners, | ||
| bool | patternWasFound | ||
| ) |
#include <opencv2/calib3d.hpp>
Renders the detected chessboard corners.
| image | Destination image. It must be an 8-bit color image. |
| patternSize | Number of inner corners per a chessboard row and column (patternSize = cv::Size(points_per_row,points_per_column)). |
| corners | Array of detected corners, the output of findChessboardCorners. |
| patternWasFound | Parameter indicating whether the complete board was found or not. The return value of findChessboardCorners should be passed here. |
The function draws individual chessboard corners detected either as red circles if the board was not found, or as colored corners connected with lines if the board was found.
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::drawFrameAxes | ( | InputOutputArray | image, |
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| InputArray | rvec, | ||
| InputArray | tvec, | ||
| float | length, | ||
| int | thickness = 3 |
||
| ) |
#include <opencv2/calib3d.hpp>
Draw axes of the world/object coordinate system from pose estimation.
| image | Input/output image. It must have 1 or 3 channels. The number of channels is not altered. |
| cameraMatrix | Input 3x3 floating-point matrix of camera intrinsic parameters. \(A = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is empty, the zero distortion coefficients are assumed. |
| rvec | Rotation vector (see Rodrigues ) that, together with tvec, brings points from the model coordinate system to the camera coordinate system. |
| tvec | Translation vector. |
| length | Length of the painted axes in the same unit than tvec (usually in meters). |
| thickness | Line thickness of the painted axes. |
This function draws the axes of the world/object coordinate system w.r.t. to the camera frame. OX is drawn in red, OY in green and OZ in blue.
Referenced by cv::LMSolver::Callback::~Callback().

| cv::Mat cv::estimateAffine2D | ( | InputArray | from, |
| InputArray | to, | ||
| OutputArray | inliers = noArray(), |
||
| int | method = RANSAC, |
||
| double | ransacReprojThreshold = 3, |
||
| size_t | maxIters = 2000, |
||
| double | confidence = 0.99, |
||
| size_t | refineIters = 10 |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes an optimal affine transformation between two 2D point sets.
It computes
\[ \begin{bmatrix} x\\ y\\ \end{bmatrix} = \begin{bmatrix} a_{11} & a_{12}\\ a_{21} & a_{22}\\ \end{bmatrix} \begin{bmatrix} X\\ Y\\ \end{bmatrix} + \begin{bmatrix} b_1\\ b_2\\ \end{bmatrix} \]
| from | First input 2D point set containing \((X,Y)\). |
| to | Second input 2D point set containing \((x,y)\). |
| inliers | Output vector indicating which points are inliers (1-inlier, 0-outlier). |
| method | Robust method used to compute transformation. The following methods are possible:
|
| ransacReprojThreshold | Maximum reprojection error in the RANSAC algorithm to consider a point as an inlier. Applies only to RANSAC. |
| maxIters | The maximum number of robust method iterations. |
| confidence | Confidence level, between 0 and 1, for the estimated transformation. Anything between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation. |
| refineIters | Maximum number of iterations of refining algorithm (Levenberg-Marquardt). Passing 0 will disable refining, so the output matrix will be output of robust method. |
\[ \begin{bmatrix} a_{11} & a_{12} & b_1\\ a_{21} & a_{22} & b_2\\ \end{bmatrix} \]
The function estimates an optimal 2D affine transformation between two 2D point sets using the selected robust algorithm.
The computed transformation is then refined further (using only inliers) with the Levenberg-Marquardt method to reduce the re-projection error even more.
| int cv::estimateAffine3D | ( | InputArray | src, |
| InputArray | dst, | ||
| OutputArray | out, | ||
| OutputArray | inliers, | ||
| double | ransacThreshold = 3, |
||
| double | confidence = 0.99 |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes an optimal affine transformation between two 3D point sets.
It computes
\[ \begin{bmatrix} x\\ y\\ z\\ \end{bmatrix} = \begin{bmatrix} a_{11} & a_{12} & a_{13}\\ a_{21} & a_{22} & a_{23}\\ a_{31} & a_{32} & a_{33}\\ \end{bmatrix} \begin{bmatrix} X\\ Y\\ Z\\ \end{bmatrix} + \begin{bmatrix} b_1\\ b_2\\ b_3\\ \end{bmatrix} \]
| src | First input 3D point set containing \((X,Y,Z)\). |
| dst | Second input 3D point set containing \((x,y,z)\). |
| out | Output 3D affine transformation matrix \(3 \times 4\) of the form \[ \begin{bmatrix} a_{11} & a_{12} & a_{13} & b_1\\ a_{21} & a_{22} & a_{23} & b_2\\ a_{31} & a_{32} & a_{33} & b_3\\ \end{bmatrix} \] |
| inliers | Output vector indicating which points are inliers (1-inlier, 0-outlier). |
| ransacThreshold | Maximum reprojection error in the RANSAC algorithm to consider a point as an inlier. |
| confidence | Confidence level, between 0 and 1, for the estimated transformation. Anything between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation. |
The function estimates an optimal 3D affine transformation between two 3D point sets using the RANSAC algorithm.
| cv::Mat cv::estimateAffinePartial2D | ( | InputArray | from, |
| InputArray | to, | ||
| OutputArray | inliers = noArray(), |
||
| int | method = RANSAC, |
||
| double | ransacReprojThreshold = 3, |
||
| size_t | maxIters = 2000, |
||
| double | confidence = 0.99, |
||
| size_t | refineIters = 10 |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes an optimal limited affine transformation with 4 degrees of freedom between two 2D point sets.
| from | First input 2D point set. |
| to | Second input 2D point set. |
| inliers | Output vector indicating which points are inliers. |
| method | Robust method used to compute transformation. The following methods are possible:
|
| ransacReprojThreshold | Maximum reprojection error in the RANSAC algorithm to consider a point as an inlier. Applies only to RANSAC. |
| maxIters | The maximum number of robust method iterations. |
| confidence | Confidence level, between 0 and 1, for the estimated transformation. Anything between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation. |
| refineIters | Maximum number of iterations of refining algorithm (Levenberg-Marquardt). Passing 0 will disable refining, so the output matrix will be output of robust method. |
The function estimates an optimal 2D affine transformation with 4 degrees of freedom limited to combinations of translation, rotation, and uniform scaling. Uses the selected algorithm for robust estimation.
The computed transformation is then refined further (using only inliers) with the Levenberg-Marquardt method to reduce the re-projection error even more.
Estimated transformation matrix is:
\[ \begin{bmatrix} \cos(\theta) \cdot s & -\sin(\theta) \cdot s & t_x \\ \sin(\theta) \cdot s & \cos(\theta) \cdot s & t_y \end{bmatrix} \]
Where \( \theta \) is the rotation angle, \( s \) the scaling factor and \( t_x, t_y \) are translations in \( x, y \) axes respectively.
| void cv::filterHomographyDecompByVisibleRefpoints | ( | InputArrayOfArrays | rotations, |
| InputArrayOfArrays | normals, | ||
| InputArray | beforePoints, | ||
| InputArray | afterPoints, | ||
| OutputArray | possibleSolutions, | ||
| InputArray | pointsMask = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Filters homography decompositions based on additional information.
| rotations | Vector of rotation matrices. |
| normals | Vector of plane normal matrices. |
| beforePoints | Vector of (rectified) visible reference points before the homography is applied |
| afterPoints | Vector of (rectified) visible reference points after the homography is applied |
| possibleSolutions | Vector of int indices representing the viable solution set after filtering |
| pointsMask | optional Mat/Vector of 8u type representing the mask for the inliers as given by the findHomography function |
This function is intended to filter the output of the decomposeHomographyMat based on additional information as described in [62] . The summary of the method: the decomposeHomographyMat function returns 2 unique solutions and their "opposites" for a total of 4 solutions. If we have access to the sets of points visible in the camera frame before and after the homography transformation is applied, we can determine which are the true potential solutions and which are the opposites by verifying which homographies are consistent with all visible reference points being in front of the camera. The inputs are left unchanged; the filtered solution set is returned as indices into the existing one.
| void cv::filterSpeckles | ( | InputOutputArray | img, |
| double | newVal, | ||
| int | maxSpeckleSize, | ||
| double | maxDiff, | ||
| InputOutputArray | buf = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Filters off small noise blobs (speckles) in the disparity map.
| img | The input 16-bit signed disparity image |
| newVal | The disparity value used to paint-off the speckles |
| maxSpeckleSize | The maximum speckle size to consider it a speckle. Larger blobs are not affected by the algorithm |
| maxDiff | Maximum difference between neighbor disparity pixels to put them into the same blob. Note that since StereoBM, StereoSGBM and may be other algorithms return a fixed-point disparity map, where disparity values are multiplied by 16, this scale factor should be taken into account when specifying this parameter value. |
| buf | The optional temporary buffer to avoid memory allocation within the function. |
| bool cv::find4QuadCornerSubpix | ( | InputArray | img, |
| InputOutputArray | corners, | ||
| Size | region_size | ||
| ) |
#include <opencv2/calib3d.hpp>
finds subpixel-accurate positions of the chessboard corners
Referenced by cv::LMSolver::Callback::~Callback().

| bool cv::findChessboardCorners | ( | InputArray | image, |
| Size | patternSize, | ||
| OutputArray | corners, | ||
| int | flags = CALIB_CB_ADAPTIVE_THRESH+CALIB_CB_NORMALIZE_IMAGE |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds the positions of internal corners of the chessboard.
| image | Source chessboard view. It must be an 8-bit grayscale or color image. |
| patternSize | Number of inner corners per a chessboard row and column ( patternSize = cv::Size(points_per_row,points_per_colum) = cv::Size(columns,rows) ). |
| corners | Output array of detected corners. |
| flags | Various operation flags that can be zero or a combination of the following values:
|
The function attempts to determine whether the input image is a view of the chessboard pattern and locate the internal chessboard corners. The function returns a non-zero value if all of the corners are found and they are placed in a certain order (row by row, left to right in every row). Otherwise, if the function fails to find all the corners or reorder them, it returns 0. For example, a regular chessboard has 8 x 8 squares and 7 x 7 internal corners, that is, points where the black squares touch each other. The detected coordinates are approximate, and to determine their positions more accurately, the function calls cornerSubPix. You also may use the function cornerSubPix with different parameters if returned coordinates are not accurate enough.
Sample usage of detecting and drawing chessboard corners: :
Referenced by cv::LMSolver::Callback::~Callback().

| bool cv::findChessboardCornersSB | ( | InputArray | image, |
| Size | patternSize, | ||
| OutputArray | corners, | ||
| int | flags = 0 |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds the positions of internal corners of the chessboard using a sector based approach.
| image | Source chessboard view. It must be an 8-bit grayscale or color image. |
| patternSize | Number of inner corners per a chessboard row and column ( patternSize = cv::Size(points_per_row,points_per_colum) = cv::Size(columns,rows) ). |
| corners | Output array of detected corners. |
| flags | Various operation flags that can be zero or a combination of the following values:
|
The function is analog to findchessboardCorners but uses a localized radon transformation approximated by box filters being more robust to all sort of noise, faster on larger images and is able to directly return the sub-pixel position of the internal chessboard corners. The Method is based on the paper [26] "Accurate Detection and Localization of Checkerboard Corners for Calibration" demonstrating that the returned sub-pixel positions are more accurate than the one returned by cornerSubPix allowing a precise camera calibration for demanding applications.

Referenced by cv::LMSolver::Callback::~Callback().

| bool cv::findCirclesGrid | ( | InputArray | image, |
| Size | patternSize, | ||
| OutputArray | centers, | ||
| int | flags, | ||
| const Ptr< FeatureDetector > & | blobDetector, | ||
| const CirclesGridFinderParameters & | parameters | ||
| ) |
#include <opencv2/calib3d.hpp>
Finds centers in the grid of circles.
| image | grid view of input circles; it must be an 8-bit grayscale or color image. |
| patternSize | number of circles per row and column ( patternSize = Size(points_per_row, points_per_colum) ). |
| centers | output array of detected centers. |
| flags | various operation flags that can be one of the following values:
|
| blobDetector | feature detector that finds blobs like dark circles on light background. |
| parameters | struct for finding circles in a grid pattern. |
The function attempts to determine whether the input image contains a grid of circles. If it is, the function locates centers of the circles. The function returns a non-zero value if all of the centers have been found and they have been placed in a certain order (row by row, left to right in every row). Otherwise, if the function fails to find all the corners or reorder them, it returns 0.
Sample usage of detecting and drawing the centers of circles: :
| bool cv::findCirclesGrid | ( | InputArray | image, |
| Size | patternSize, | ||
| OutputArray | centers, | ||
| int | flags = CALIB_CB_SYMMETRIC_GRID, |
||
| const Ptr< FeatureDetector > & | blobDetector = SimpleBlobDetector::create() |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| Mat cv::findEssentialMat | ( | InputArray | points1, |
| InputArray | points2, | ||
| InputArray | cameraMatrix, | ||
| int | method = RANSAC, |
||
| double | prob = 0.999, |
||
| double | threshold = 1.0, |
||
| OutputArray | mask = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Calculates an essential matrix from the corresponding points in two images.
| points1 | Array of N (N >= 5) 2D points from the first image. The point coordinates should be floating-point (single or double precision). |
| points2 | Array of the second image points of the same size and format as points1 . |
| cameraMatrix | Camera matrix \(K = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . Note that this function assumes that points1 and points2 are feature points from cameras with the same camera matrix. |
| method | Method for computing an essential matrix.
|
| prob | Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of confidence (probability) that the estimated matrix is correct. |
| threshold | Parameter used for RANSAC. It is the maximum distance from a point to an epipolar line in pixels, beyond which the point is considered an outlier and is not used for computing the final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the point localization, image resolution, and the image noise. |
| mask | Output array of N elements, every element of which is set to 0 for outliers and to 1 for the other points. The array is computed only in the RANSAC and LMedS methods. |
This function estimates essential matrix based on the five-point algorithm solver in [71] . [87] is also a related. The epipolar geometry is described by the following equation:
\[[p_2; 1]^T K^{-T} E K^{-1} [p_1; 1] = 0\]
where \(E\) is an essential matrix, \(p_1\) and \(p_2\) are corresponding points in the first and the second images, respectively. The result of this function may be passed further to decomposeEssentialMat or recoverPose to recover the relative pose between cameras.
| Mat cv::findEssentialMat | ( | InputArray | points1, |
| InputArray | points2, | ||
| double | focal = 1.0, |
||
| Point2d | pp = Point2d(0, 0), |
||
| int | method = RANSAC, |
||
| double | prob = 0.999, |
||
| double | threshold = 1.0, |
||
| OutputArray | mask = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| points1 | Array of N (N >= 5) 2D points from the first image. The point coordinates should be floating-point (single or double precision). |
| points2 | Array of the second image points of the same size and format as points1 . |
| focal | focal length of the camera. Note that this function assumes that points1 and points2 are feature points from cameras with same focal length and principal point. |
| pp | principal point of the camera. |
| method | Method for computing a fundamental matrix.
|
| threshold | Parameter used for RANSAC. It is the maximum distance from a point to an epipolar line in pixels, beyond which the point is considered an outlier and is not used for computing the final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the point localization, image resolution, and the image noise. |
| prob | Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of confidence (probability) that the estimated matrix is correct. |
| mask | Output array of N elements, every element of which is set to 0 for outliers and to 1 for the other points. The array is computed only in the RANSAC and LMedS methods. |
This function differs from the one above that it computes camera matrix from focal length and principal point:
\[K = \begin{bmatrix} f & 0 & x_{pp} \\ 0 & f & y_{pp} \\ 0 & 0 & 1 \end{bmatrix}\]
| Mat cv::findFundamentalMat | ( | InputArray | points1, |
| InputArray | points2, | ||
| int | method = FM_RANSAC, |
||
| double | ransacReprojThreshold = 3., |
||
| double | confidence = 0.99, |
||
| OutputArray | mask = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Calculates a fundamental matrix from the corresponding points in two images.
| points1 | Array of N points from the first image. The point coordinates should be floating-point (single or double precision). |
| points2 | Array of the second image points of the same size and format as points1 . |
| method | Method for computing a fundamental matrix.
|
| ransacReprojThreshold | Parameter used only for RANSAC. It is the maximum distance from a point to an epipolar line in pixels, beyond which the point is considered an outlier and is not used for computing the final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the point localization, image resolution, and the image noise. |
| confidence | Parameter used for the RANSAC and LMedS methods only. It specifies a desirable level of confidence (probability) that the estimated matrix is correct. |
| mask | The epipolar geometry is described by the following equation: |
\[[p_2; 1]^T F [p_1; 1] = 0\]
where \(F\) is a fundamental matrix, \(p_1\) and \(p_2\) are corresponding points in the first and the second images, respectively.
The function calculates the fundamental matrix using one of four methods listed above and returns the found fundamental matrix. Normally just one matrix is found. But in case of the 7-point algorithm, the function may return up to 3 solutions ( \(9 \times 3\) matrix that stores all 3 matrices sequentially).
The calculated fundamental matrix may be passed further to computeCorrespondEpilines that finds the epipolar lines corresponding to the specified points. It can also be passed to stereoRectifyUncalibrated to compute the rectification transformation. :
| Mat cv::findFundamentalMat | ( | InputArray | points1, |
| InputArray | points2, | ||
| OutputArray | mask, | ||
| int | method = FM_RANSAC, |
||
| double | ransacReprojThreshold = 3., |
||
| double | confidence = 0.99 |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| Mat cv::findHomography | ( | InputArray | srcPoints, |
| InputArray | dstPoints, | ||
| int | method = 0, |
||
| double | ransacReprojThreshold = 3, |
||
| OutputArray | mask = noArray(), |
||
| const int | maxIters = 2000, |
||
| const double | confidence = 0.995 |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds a perspective transformation between two planes.
| srcPoints | Coordinates of the points in the original plane, a matrix of the type CV_32FC2 or vector<Point2f> . |
| dstPoints | Coordinates of the points in the target plane, a matrix of the type CV_32FC2 or a vector<Point2f> . |
| method | Method used to compute a homography matrix. The following methods are possible:
|
| ransacReprojThreshold | Maximum allowed reprojection error to treat a point pair as an inlier (used in the RANSAC and RHO methods only). That is, if \[\| \texttt{dstPoints} _i - \texttt{convertPointsHomogeneous} ( \texttt{H} * \texttt{srcPoints} _i) \|_2 > \texttt{ransacReprojThreshold}\] then the point \(i\) is considered as an outlier. If srcPoints and dstPoints are measured in pixels, it usually makes sense to set this parameter somewhere in the range of 1 to 10. |
| mask | Optional output mask set by a robust method ( RANSAC or LMEDS ). Note that the input mask values are ignored. |
| maxIters | The maximum number of RANSAC iterations. |
| confidence | Confidence level, between 0 and 1. |
The function finds and returns the perspective transformation \(H\) between the source and the destination planes:
\[s_i \vecthree{x'_i}{y'_i}{1} \sim H \vecthree{x_i}{y_i}{1}\]
so that the back-projection error
\[\sum _i \left ( x'_i- \frac{h_{11} x_i + h_{12} y_i + h_{13}}{h_{31} x_i + h_{32} y_i + h_{33}} \right )^2+ \left ( y'_i- \frac{h_{21} x_i + h_{22} y_i + h_{23}}{h_{31} x_i + h_{32} y_i + h_{33}} \right )^2\]
is minimized. If the parameter method is set to the default value 0, the function uses all the point pairs to compute an initial homography estimate with a simple least-squares scheme.
However, if not all of the point pairs ( \(srcPoints_i\), \(dstPoints_i\) ) fit the rigid perspective transformation (that is, there are some outliers), this initial estimate will be poor. In this case, you can use one of the three robust methods. The methods RANSAC, LMeDS and RHO try many different random subsets of the corresponding point pairs (of four pairs each, collinear pairs are discarded), estimate the homography matrix using this subset and a simple least-squares algorithm, and then compute the quality/goodness of the computed homography (which is the number of inliers for RANSAC or the least median re-projection error for LMeDS). The best subset is then used to produce the initial estimate of the homography matrix and the mask of inliers/outliers.
Regardless of the method, robust or not, the computed homography matrix is refined further (using inliers only in case of a robust method) with the Levenberg-Marquardt method to reduce the re-projection error even more.
The methods RANSAC and RHO can handle practically any ratio of outliers but need a threshold to distinguish inliers from outliers. The method LMeDS does not need any threshold but it works correctly only when there are more than 50% of inliers. Finally, if there are no outliers and the noise is rather small, use the default method (method=0).
The function is used to find initial intrinsic and extrinsic matrices. Homography matrix is determined up to a scale. Thus, it is normalized so that \(h_{33}=1\). Note that whenever an \(H\) matrix cannot be estimated, an empty one will be returned.
Referenced by cv::LMSolver::Callback::~Callback().

| Mat cv::findHomography | ( | InputArray | srcPoints, |
| InputArray | dstPoints, | ||
| OutputArray | mask, | ||
| int | method = 0, |
||
| double | ransacReprojThreshold = 3 |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| Mat cv::getDefaultNewCameraMatrix | ( | InputArray | cameraMatrix, |
| Size | imgsize = Size(), |
||
| bool | centerPrincipalPoint = false |
||
| ) |
#include <opencv2/calib3d.hpp>
Returns the default new camera matrix.
The function returns the camera matrix that is either an exact copy of the input cameraMatrix (when centerPrinicipalPoint=false ), or the modified one (when centerPrincipalPoint=true).
In the latter case, the new camera matrix will be:
\[\begin{bmatrix} f_x && 0 && ( \texttt{imgSize.width} -1)*0.5 \\ 0 && f_y && ( \texttt{imgSize.height} -1)*0.5 \\ 0 && 0 && 1 \end{bmatrix} ,\]
where \(f_x\) and \(f_y\) are \((0,0)\) and \((1,1)\) elements of cameraMatrix, respectively.
By default, the undistortion functions in OpenCV (see initUndistortRectifyMap, undistort) do not move the principal point. However, when you work with stereo, it is important to move the principal points in both views to the same y-coordinate (which is required by most of stereo correspondence algorithms), and may be to the same x-coordinate too. So, you can form the new camera matrix for each view where the principal points are located at the center.
| cameraMatrix | Input camera matrix. |
| imgsize | Camera view image size in pixels. |
| centerPrincipalPoint | Location of the principal point in the new camera matrix. The parameter indicates whether this location should be at the image center or not. |
Referenced by cv::initWideAngleProjMap().

| Mat cv::getOptimalNewCameraMatrix | ( | InputArray | cameraMatrix, |
| InputArray | distCoeffs, | ||
| Size | imageSize, | ||
| double | alpha, | ||
| Size | newImgSize = Size(), |
||
| Rect * | validPixROI = 0, |
||
| bool | centerPrincipalPoint = false |
||
| ) |
#include <opencv2/calib3d.hpp>
Returns the new camera matrix based on the free scaling parameter.
| cameraMatrix | Input camera matrix. |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| imageSize | Original image size. |
| alpha | Free scaling parameter between 0 (when all the pixels in the undistorted image are valid) and 1 (when all the source image pixels are retained in the undistorted image). See stereoRectify for details. |
| newImgSize | Image size after rectification. By default, it is set to imageSize . |
| validPixROI | Optional output rectangle that outlines all-good-pixels region in the undistorted image. See roi1, roi2 description in stereoRectify . |
| centerPrincipalPoint | Optional flag that indicates whether in the new camera matrix the principal point should be at the image center or not. By default, the principal point is chosen to best fit a subset of the source image (determined by alpha) to the corrected image. |
The function computes and returns the optimal new camera matrix based on the free scaling parameter. By varying this parameter, you may retrieve only sensible pixels alpha=0 , keep all the original image pixels if there is valuable information in the corners alpha=1 , or get something in between. When alpha>0 , the undistorted result is likely to have some black pixels corresponding to "virtual" pixels outside of the captured distorted image. The original camera matrix, distortion coefficients, the computed new camera matrix, and newImageSize should be passed to initUndistortRectifyMap to produce the maps for remap .
| Rect cv::getValidDisparityROI | ( | Rect | roi1, |
| Rect | roi2, | ||
| int | minDisparity, | ||
| int | numberOfDisparities, | ||
| int | SADWindowSize | ||
| ) |
#include <opencv2/calib3d.hpp>
computes valid disparity ROI from the valid ROIs of the rectified images (that are returned by cv::stereoRectify())
| Mat cv::initCameraMatrix2D | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints, | ||
| Size | imageSize, | ||
| double | aspectRatio = 1.0 |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds an initial camera matrix from 3D-2D point correspondences.
| objectPoints | Vector of vectors of the calibration pattern points in the calibration pattern coordinate space. In the old interface all the per-view vectors are concatenated. See calibrateCamera for details. |
| imagePoints | Vector of vectors of the projections of the calibration pattern points. In the old interface all the per-view vectors are concatenated. |
| imageSize | Image size in pixels used to initialize the principal point. |
| aspectRatio | If it is zero or negative, both \(f_x\) and \(f_y\) are estimated independently. Otherwise, \(f_x = f_y * \texttt{aspectRatio}\) . |
The function estimates and returns an initial camera matrix for the camera calibration process. Currently, the function only supports planar calibration patterns, which are patterns where each object point has z-coordinate =0.
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::initUndistortRectifyMap | ( | InputArray | cameraMatrix, |
| InputArray | distCoeffs, | ||
| InputArray | R, | ||
| InputArray | newCameraMatrix, | ||
| Size | size, | ||
| int | m1type, | ||
| OutputArray | map1, | ||
| OutputArray | map2 | ||
| ) |
#include <opencv2/calib3d.hpp>
Computes the undistortion and rectification transformation map.
The function computes the joint undistortion and rectification transformation and represents the result in the form of maps for remap. The undistorted image looks like original, as if it is captured with a camera using the camera matrix =newCameraMatrix and zero distortion. In case of a monocular camera, newCameraMatrix is usually equal to cameraMatrix, or it can be computed by getOptimalNewCameraMatrix for a better control over scaling. In case of a stereo camera, newCameraMatrix is normally set to P1 or P2 computed by stereoRectify .
Also, this new camera is oriented differently in the coordinate space, according to R. That, for example, helps to align two heads of a stereo camera so that the epipolar lines on both images become horizontal and have the same y- coordinate (in case of a horizontally aligned stereo camera).
The function actually builds the maps for the inverse mapping algorithm that is used by remap. That is, for each pixel \((u, v)\) in the destination (corrected and rectified) image, the function computes the corresponding coordinates in the source image (that is, in the original image from camera). The following process is applied:
\[ \begin{array}{l} x \leftarrow (u - {c'}_x)/{f'}_x \\ y \leftarrow (v - {c'}_y)/{f'}_y \\ {[X\,Y\,W]} ^T \leftarrow R^{-1}*[x \, y \, 1]^T \\ x' \leftarrow X/W \\ y' \leftarrow Y/W \\ r^2 \leftarrow x'^2 + y'^2 \\ x'' \leftarrow x' \frac{1 + k_1 r^2 + k_2 r^4 + k_3 r^6}{1 + k_4 r^2 + k_5 r^4 + k_6 r^6} + 2p_1 x' y' + p_2(r^2 + 2 x'^2) + s_1 r^2 + s_2 r^4\\ y'' \leftarrow y' \frac{1 + k_1 r^2 + k_2 r^4 + k_3 r^6}{1 + k_4 r^2 + k_5 r^4 + k_6 r^6} + p_1 (r^2 + 2 y'^2) + 2 p_2 x' y' + s_3 r^2 + s_4 r^4 \\ s\vecthree{x'''}{y'''}{1} = \vecthreethree{R_{33}(\tau_x, \tau_y)}{0}{-R_{13}((\tau_x, \tau_y)} {0}{R_{33}(\tau_x, \tau_y)}{-R_{23}(\tau_x, \tau_y)} {0}{0}{1} R(\tau_x, \tau_y) \vecthree{x''}{y''}{1}\\ map_x(u,v) \leftarrow x''' f_x + c_x \\ map_y(u,v) \leftarrow y''' f_y + c_y \end{array} \]
where \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6[, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) are the distortion coefficients.
In case of a stereo camera, this function is called twice: once for each camera head, after stereoRectify, which in its turn is called after stereoCalibrate. But if the stereo camera was not calibrated, it is still possible to compute the rectification transformations directly from the fundamental matrix using stereoRectifyUncalibrated. For each camera, the function computes homography H as the rectification transformation in a pixel domain, not a rotation matrix R in 3D space. R can be computed from H as
\[\texttt{R} = \texttt{cameraMatrix} ^{-1} \cdot \texttt{H} \cdot \texttt{cameraMatrix}\]
where cameraMatrix can be chosen arbitrarily.
| cameraMatrix | Input camera matrix \(A=\vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6[, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| R | Optional rectification transformation in the object space (3x3 matrix). R1 or R2 , computed by stereoRectify can be passed here. If the matrix is empty, the identity transformation is assumed. In cvInitUndistortMap R assumed to be an identity matrix. |
| newCameraMatrix | New camera matrix \(A'=\vecthreethree{f_x'}{0}{c_x'}{0}{f_y'}{c_y'}{0}{0}{1}\). |
| size | Undistorted image size. |
| m1type | Type of the first output map that can be CV_32FC1, CV_32FC2 or CV_16SC2, see convertMaps |
| map1 | The first output map. |
| map2 | The second output map. |
| float cv::initWideAngleProjMap | ( | InputArray | cameraMatrix, |
| InputArray | distCoeffs, | ||
| Size | imageSize, | ||
| int | destImageWidth, | ||
| int | m1type, | ||
| OutputArray | map1, | ||
| OutputArray | map2, | ||
| enum UndistortTypes | projType = PROJ_SPHERICAL_EQRECT, |
||
| double | alpha = 0 |
||
| ) |
#include <opencv2/calib3d.hpp>
initializes maps for remap for wide-angle
Referenced by cv::initWideAngleProjMap().

|
inlinestatic |
#include <opencv2/calib3d.hpp>
References CV_EXPORTS_AS, CV_EXPORTS_W, cv::getDefaultNewCameraMatrix(), cv::initWideAngleProjMap(), cv::noArray(), and cv::undistortPoints().

| void cv::matMulDeriv | ( | InputArray | A, |
| InputArray | B, | ||
| OutputArray | dABdA, | ||
| OutputArray | dABdB | ||
| ) |
#include <opencv2/calib3d.hpp>
Computes partial derivatives of the matrix product for each multiplied matrix.
| A | First multiplied matrix. |
| B | Second multiplied matrix. |
| dABdA | First output derivative matrix d(A*B)/dA of size \(\texttt{A.rows*B.cols} \times {A.rows*A.cols}\) . |
| dABdB | Second output derivative matrix d(A*B)/dB of size \(\texttt{A.rows*B.cols} \times {B.rows*B.cols}\) . |
The function computes partial derivatives of the elements of the matrix product \(A*B\) with regard to the elements of each of the two input matrices. The function is used to compute the Jacobian matrices in stereoCalibrate but can also be used in any other similar optimization function.
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::projectPoints | ( | InputArray | objectPoints, |
| InputArray | rvec, | ||
| InputArray | tvec, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| OutputArray | imagePoints, | ||
| OutputArray | jacobian = noArray(), |
||
| double | aspectRatio = 0 |
||
| ) |
#include <opencv2/calib3d.hpp>
Projects 3D points to an image plane.
| objectPoints | Array of object points, 3xN/Nx3 1-channel or 1xN/Nx1 3-channel (or vector<Point3f> ), where N is the number of points in the view. |
| rvec | Rotation vector. See Rodrigues for details. |
| tvec | Translation vector. |
| cameraMatrix | Camera matrix \(A = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{_1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is empty, the zero distortion coefficients are assumed. |
| imagePoints | Output array of image points, 1xN/Nx1 2-channel, or vector<Point2f> . |
| jacobian | Optional output 2Nx(10+<numDistCoeffs>) jacobian matrix of derivatives of image points with respect to components of the rotation vector, translation vector, focal lengths, coordinates of the principal point and the distortion coefficients. In the old interface different components of the jacobian are returned via different output parameters. |
| aspectRatio | Optional "fixed aspect ratio" parameter. If the parameter is not 0, the function assumes that the aspect ratio (fx/fy) is fixed and correspondingly adjusts the jacobian matrix. |
The function computes projections of 3D points to the image plane given intrinsic and extrinsic camera parameters. Optionally, the function computes Jacobians - matrices of partial derivatives of image points coordinates (as functions of all the input parameters) with respect to the particular parameters, intrinsic and/or extrinsic. The Jacobians are used during the global optimization in calibrateCamera, solvePnP, and stereoCalibrate . The function itself can also be used to compute a re-projection error given the current intrinsic and extrinsic parameters.
Referenced by cv::LMSolver::Callback::~Callback().

| int cv::recoverPose | ( | InputArray | E, |
| InputArray | points1, | ||
| InputArray | points2, | ||
| InputArray | cameraMatrix, | ||
| OutputArray | R, | ||
| OutputArray | t, | ||
| InputOutputArray | mask = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Recover relative camera rotation and translation from an estimated essential matrix and the corresponding points in two images, using cheirality check.
Returns the number of inliers which pass the check.
| E | The input essential matrix. |
| points1 | Array of N 2D points from the first image. The point coordinates should be floating-point (single or double precision). |
| points2 | Array of the second image points of the same size and format as points1 . |
| cameraMatrix | Camera matrix \(K = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . Note that this function assumes that points1 and points2 are feature points from cameras with the same camera matrix. |
| R | Recovered relative rotation. |
| t | Recovered relative translation. |
| mask | Input/output mask for inliers in points1 and points2. : If it is not empty, then it marks inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to recover pose. In the output mask only inliers which pass the cheirality check. This function decomposes an essential matrix using decomposeEssentialMat and then verifies possible pose hypotheses by doing cheirality check. The cheirality check basically means that the triangulated 3D points should have positive depth. Some details can be found in [71] . |
This function can be used to process output E and mask from findEssentialMat. In this scenario, points1 and points2 are the same input for findEssentialMat. :
| int cv::recoverPose | ( | InputArray | E, |
| InputArray | points1, | ||
| InputArray | points2, | ||
| OutputArray | R, | ||
| OutputArray | t, | ||
| double | focal = 1.0, |
||
| Point2d | pp = Point2d(0, 0), |
||
| InputOutputArray | mask = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| E | The input essential matrix. |
| points1 | Array of N 2D points from the first image. The point coordinates should be floating-point (single or double precision). |
| points2 | Array of the second image points of the same size and format as points1 . |
| R | Recovered relative rotation. |
| t | Recovered relative translation. |
| focal | Focal length of the camera. Note that this function assumes that points1 and points2 are feature points from cameras with same focal length and principal point. |
| pp | principal point of the camera. |
| mask | Input/output mask for inliers in points1 and points2. : If it is not empty, then it marks inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to recover pose. In the output mask only inliers which pass the cheirality check. |
This function differs from the one above that it computes camera matrix from focal length and principal point:
\[K = \begin{bmatrix} f & 0 & x_{pp} \\ 0 & f & y_{pp} \\ 0 & 0 & 1 \end{bmatrix}\]
| int cv::recoverPose | ( | InputArray | E, |
| InputArray | points1, | ||
| InputArray | points2, | ||
| InputArray | cameraMatrix, | ||
| OutputArray | R, | ||
| OutputArray | t, | ||
| double | distanceThresh, | ||
| InputOutputArray | mask = noArray(), |
||
| OutputArray | triangulatedPoints = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| E | The input essential matrix. |
| points1 | Array of N 2D points from the first image. The point coordinates should be floating-point (single or double precision). |
| points2 | Array of the second image points of the same size and format as points1. |
| cameraMatrix | Camera matrix \(K = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . Note that this function assumes that points1 and points2 are feature points from cameras with the same camera matrix. |
| R | Recovered relative rotation. |
| t | Recovered relative translation. |
| distanceThresh | threshold distance which is used to filter out far away points (i.e. infinite points). |
| mask | Input/output mask for inliers in points1 and points2. : If it is not empty, then it marks inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to recover pose. In the output mask only inliers which pass the cheirality check. |
| triangulatedPoints | 3d points which were reconstructed by triangulation. |
| float cv::rectify3Collinear | ( | InputArray | cameraMatrix1, |
| InputArray | distCoeffs1, | ||
| InputArray | cameraMatrix2, | ||
| InputArray | distCoeffs2, | ||
| InputArray | cameraMatrix3, | ||
| InputArray | distCoeffs3, | ||
| InputArrayOfArrays | imgpt1, | ||
| InputArrayOfArrays | imgpt3, | ||
| Size | imageSize, | ||
| InputArray | R12, | ||
| InputArray | T12, | ||
| InputArray | R13, | ||
| InputArray | T13, | ||
| OutputArray | R1, | ||
| OutputArray | R2, | ||
| OutputArray | R3, | ||
| OutputArray | P1, | ||
| OutputArray | P2, | ||
| OutputArray | P3, | ||
| OutputArray | Q, | ||
| double | alpha, | ||
| Size | newImgSize, | ||
| Rect * | roi1, | ||
| Rect * | roi2, | ||
| int | flags | ||
| ) |
#include <opencv2/calib3d.hpp>
computes the rectification transformations for 3-head camera, where all the heads are on the same line.
| void cv::reprojectImageTo3D | ( | InputArray | disparity, |
| OutputArray | _3dImage, | ||
| InputArray | Q, | ||
| bool | handleMissingValues = false, |
||
| int | ddepth = -1 |
||
| ) |
#include <opencv2/calib3d.hpp>
Reprojects a disparity image to 3D space.
| disparity | Input single-channel 8-bit unsigned, 16-bit signed, 32-bit signed or 32-bit floating-point disparity image. If 16-bit signed format is used, the values are assumed to have no fractional bits. |
| _3dImage | Output 3-channel floating-point image of the same size as disparity . Each element of _3dImage(x,y) contains 3D coordinates of the point (x,y) computed from the disparity map. |
| Q | \(4 \times 4\) perspective transformation matrix that can be obtained with stereoRectify. |
| handleMissingValues | Indicates, whether the function should handle missing values (i.e. points where the disparity was not computed). If handleMissingValues=true, then pixels with the minimal disparity that corresponds to the outliers (see StereoMatcher::compute ) are transformed to 3D points with a very large Z value (currently set to 10000). |
| ddepth | The optional output array depth. If it is -1, the output image will have CV_32F depth. ddepth can also be set to CV_16S, CV_32S or CV_32F. |
The function transforms a single-channel disparity map to a 3-channel image representing a 3D surface. That is, for each pixel (x,y) and the corresponding disparity d=disparity(x,y) , it computes:
\[\begin{array}{l} [X \; Y \; Z \; W]^T = \texttt{Q} *[x \; y \; \texttt{disparity} (x,y) \; 1]^T \\ \texttt{\_3dImage} (x,y) = (X/W, \; Y/W, \; Z/W) \end{array}\]
The matrix Q can be an arbitrary \(4 \times 4\) matrix (for example, the one computed by stereoRectify). To reproject a sparse set of points {(x,y,d),...} to 3D space, use perspectiveTransform .
| void cv::Rodrigues | ( | InputArray | src, |
| OutputArray | dst, | ||
| OutputArray | jacobian = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Converts a rotation matrix to a rotation vector or vice versa.
| src | Input rotation vector (3x1 or 1x3) or rotation matrix (3x3). |
| dst | Output rotation matrix (3x3) or rotation vector (3x1 or 1x3), respectively. |
| jacobian | Optional output Jacobian matrix, 3x9 or 9x3, which is a matrix of partial derivatives of the output array components with respect to the input array components. |
\[\begin{array}{l} \theta \leftarrow norm(r) \\ r \leftarrow r/ \theta \\ R = \cos{\theta} I + (1- \cos{\theta} ) r r^T + \sin{\theta} \vecthreethree{0}{-r_z}{r_y}{r_z}{0}{-r_x}{-r_y}{r_x}{0} \end{array}\]
Inverse transformation can be also done easily, since
\[\sin ( \theta ) \vecthreethree{0}{-r_z}{r_y}{r_z}{0}{-r_x}{-r_y}{r_x}{0} = \frac{R - R^T}{2}\]
A rotation vector is a convenient and most compact representation of a rotation matrix (since any rotation matrix has just 3 degrees of freedom). The representation is used in the global 3D geometry optimization procedures like calibrateCamera, stereoCalibrate, or solvePnP .
| Vec3d cv::RQDecomp3x3 | ( | InputArray | src, |
| OutputArray | mtxR, | ||
| OutputArray | mtxQ, | ||
| OutputArray | Qx = noArray(), |
||
| OutputArray | Qy = noArray(), |
||
| OutputArray | Qz = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes an RQ decomposition of 3x3 matrices.
| src | 3x3 input matrix. |
| mtxR | Output 3x3 upper-triangular matrix. |
| mtxQ | Output 3x3 orthogonal matrix. |
| Qx | Optional output 3x3 rotation matrix around x-axis. |
| Qy | Optional output 3x3 rotation matrix around y-axis. |
| Qz | Optional output 3x3 rotation matrix around z-axis. |
The function computes a RQ decomposition using the given rotations. This function is used in decomposeProjectionMatrix to decompose the left 3x3 submatrix of a projection matrix into a camera and a rotation matrix.
It optionally returns three rotation matrices, one for each axis, and the three Euler angles in degrees (as the return value) that could be used in OpenGL. Note, there is always more than one sequence of rotations about the three principal axes that results in the same orientation of an object, e.g. see [86] . Returned tree rotation matrices and corresponding three Euler angles are only one of the possible solutions.
Referenced by cv::LMSolver::Callback::~Callback().

| double cv::sampsonDistance | ( | InputArray | pt1, |
| InputArray | pt2, | ||
| InputArray | F | ||
| ) |
#include <opencv2/calib3d.hpp>
Calculates the Sampson Distance between two points.
The function cv::sampsonDistance calculates and returns the first order approximation of the geometric error as:
\[ sd( \texttt{pt1} , \texttt{pt2} )= \frac{(\texttt{pt2}^t \cdot \texttt{F} \cdot \texttt{pt1})^2} {((\texttt{F} \cdot \texttt{pt1})(0))^2 + ((\texttt{F} \cdot \texttt{pt1})(1))^2 + ((\texttt{F}^t \cdot \texttt{pt2})(0))^2 + ((\texttt{F}^t \cdot \texttt{pt2})(1))^2} \]
The fundamental matrix may be calculated using the cv::findFundamentalMat function. See [40] 11.4.3 for details.
| pt1 | first homogeneous 2d point |
| pt2 | second homogeneous 2d point |
| F | fundamental matrix |
| int cv::solveP3P | ( | InputArray | objectPoints, |
| InputArray | imagePoints, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| int | flags | ||
| ) |
#include <opencv2/calib3d.hpp>
Finds an object pose from 3 3D-2D point correspondences.
| objectPoints | Array of object points in the object coordinate space, 3x3 1-channel or 1x3/3x1 3-channel. vector<Point3f> can be also passed here. |
| imagePoints | Array of corresponding image points, 3x2 1-channel or 1x3/3x1 2-channel. vector<Point2f> can be also passed here. |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{fx}{0}{cx}{0}{fy}{cy}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvecs | Output rotation vectors (see Rodrigues ) that, together with tvecs, brings points from the model coordinate system to the camera coordinate system. A P3P problem has up to 4 solutions. |
| tvecs | Output translation vectors. |
| flags | Method for solving a P3P problem:
|
The function estimates the object pose given 3 object points, their corresponding image projections, as well as the camera matrix and the distortion coefficients.
Referenced by cv::LMSolver::Callback::~Callback().

| bool cv::solvePnP | ( | InputArray | objectPoints, |
| InputArray | imagePoints, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| OutputArray | rvec, | ||
| OutputArray | tvec, | ||
| bool | useExtrinsicGuess = false, |
||
| int | flags = SOLVEPNP_ITERATIVE |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds an object pose from 3D-2D point correspondences.
This function returns the rotation and the translation vectors that transform a 3D point expressed in the object coordinate frame to the camera coordinate frame, using different methods:
| objectPoints | Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector<Point3f> can be also passed here. |
| imagePoints | Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points. vector<Point2f> can be also passed here. |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{fx}{0}{cx}{0}{fy}{cy}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvec | Output rotation vector (see Rodrigues ) that, together with tvec, brings points from the model coordinate system to the camera coordinate system. |
| tvec | Output translation vector. |
| useExtrinsicGuess | Parameter used for SOLVEPNP_ITERATIVE. If true (1), the function uses the provided rvec and tvec values as initial approximations of the rotation and translation vectors, respectively, and further optimizes them. |
| flags | Method for solving a PnP problem:
|
The function estimates the object pose given a set of object points, their corresponding image projections, as well as the camera matrix and the distortion coefficients, see the figure below (more precisely, the X-axis of the camera frame is pointing to the right, the Y-axis downward and the Z-axis forward).
Points expressed in the world frame \( \bf{X}_w \) are projected into the image plane \( \left[ u, v \right] \) using the perspective projection model \( \Pi \) and the camera intrinsic parameters matrix \( \bf{A} \):
\[ \begin{align*} \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} &= \bf{A} \hspace{0.1em} \Pi \hspace{0.2em} ^{c}\bf{M}_w \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \\ \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} &= \begin{bmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} \begin{bmatrix} r_{11} & r_{12} & r_{13} & t_x \\ r_{21} & r_{22} & r_{23} & t_y \\ r_{31} & r_{32} & r_{33} & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \end{align*} \]
The estimated pose is thus the rotation (rvec) and the translation (tvec) vectors that allow transforming a 3D point expressed in the world frame into the camera frame:
\[ \begin{align*} \begin{bmatrix} X_c \\ Y_c \\ Z_c \\ 1 \end{bmatrix} &= \hspace{0.2em} ^{c}\bf{M}_w \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \\ \begin{bmatrix} X_c \\ Y_c \\ Z_c \\ 1 \end{bmatrix} &= \begin{bmatrix} r_{11} & r_{12} & r_{13} & t_x \\ r_{21} & r_{22} & r_{23} & t_y \\ r_{31} & r_{32} & r_{33} & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \end{align*} \]
useExtrinsicGuess=true, the minimum number of points is 3 (3 points are sufficient to compute a pose but there are up to 4 solutions). The initial solution should be close to the global solution to converge.Referenced by cv::LMSolver::Callback::~Callback().

| int cv::solvePnPGeneric | ( | InputArray | objectPoints, |
| InputArray | imagePoints, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| OutputArrayOfArrays | rvecs, | ||
| OutputArrayOfArrays | tvecs, | ||
| bool | useExtrinsicGuess = false, |
||
| SolvePnPMethod | flags = SOLVEPNP_ITERATIVE, |
||
| InputArray | rvec = noArray(), |
||
| InputArray | tvec = noArray(), |
||
| OutputArray | reprojectionError = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds an object pose from 3D-2D point correspondences.
This function returns a list of all the possible solutions (a solution is a <rotation vector, translation vector> couple), depending on the number of input points and the chosen method:
| objectPoints | Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector<Point3f> can be also passed here. |
| imagePoints | Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points. vector<Point2f> can be also passed here. |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{fx}{0}{cx}{0}{fy}{cy}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvecs | Vector of output rotation vectors (see Rodrigues ) that, together with tvecs, brings points from the model coordinate system to the camera coordinate system. |
| tvecs | Vector of output translation vectors. |
| useExtrinsicGuess | Parameter used for SOLVEPNP_ITERATIVE. If true (1), the function uses the provided rvec and tvec values as initial approximations of the rotation and translation vectors, respectively, and further optimizes them. |
| flags | Method for solving a PnP problem:
|
| rvec | Rotation vector used to initialize an iterative PnP refinement algorithm, when flag is SOLVEPNP_ITERATIVE and useExtrinsicGuess is set to true. |
| tvec | Translation vector used to initialize an iterative PnP refinement algorithm, when flag is SOLVEPNP_ITERATIVE and useExtrinsicGuess is set to true. |
| reprojectionError | Optional vector of reprojection error, that is the RMS error ( \( \text{RMSE} = \sqrt{\frac{\sum_{i}^{N} \left ( \hat{y_i} - y_i \right )^2}{N}} \)) between the input image points and the 3D object points projected with the estimated pose. |
The function estimates the object pose given a set of object points, their corresponding image projections, as well as the camera matrix and the distortion coefficients, see the figure below (more precisely, the X-axis of the camera frame is pointing to the right, the Y-axis downward and the Z-axis forward).
Points expressed in the world frame \( \bf{X}_w \) are projected into the image plane \( \left[ u, v \right] \) using the perspective projection model \( \Pi \) and the camera intrinsic parameters matrix \( \bf{A} \):
\[ \begin{align*} \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} &= \bf{A} \hspace{0.1em} \Pi \hspace{0.2em} ^{c}\bf{M}_w \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \\ \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} &= \begin{bmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} \begin{bmatrix} r_{11} & r_{12} & r_{13} & t_x \\ r_{21} & r_{22} & r_{23} & t_y \\ r_{31} & r_{32} & r_{33} & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \end{align*} \]
The estimated pose is thus the rotation (rvec) and the translation (tvec) vectors that allow transforming a 3D point expressed in the world frame into the camera frame:
\[ \begin{align*} \begin{bmatrix} X_c \\ Y_c \\ Z_c \\ 1 \end{bmatrix} &= \hspace{0.2em} ^{c}\bf{M}_w \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \\ \begin{bmatrix} X_c \\ Y_c \\ Z_c \\ 1 \end{bmatrix} &= \begin{bmatrix} r_{11} & r_{12} & r_{13} & t_x \\ r_{21} & r_{22} & r_{23} & t_y \\ r_{31} & r_{32} & r_{33} & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} X_{w} \\ Y_{w} \\ Z_{w} \\ 1 \end{bmatrix} \end{align*} \]
useExtrinsicGuess=true, the minimum number of points is 3 (3 points are sufficient to compute a pose but there are up to 4 solutions). The initial solution should be close to the global solution to converge.Referenced by cv::LMSolver::Callback::~Callback().

| bool cv::solvePnPRansac | ( | InputArray | objectPoints, |
| InputArray | imagePoints, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| OutputArray | rvec, | ||
| OutputArray | tvec, | ||
| bool | useExtrinsicGuess = false, |
||
| int | iterationsCount = 100, |
||
| float | reprojectionError = 8.0, |
||
| double | confidence = 0.99, |
||
| OutputArray | inliers = noArray(), |
||
| int | flags = SOLVEPNP_ITERATIVE |
||
| ) |
#include <opencv2/calib3d.hpp>
Finds an object pose from 3D-2D point correspondences using the RANSAC scheme.
| objectPoints | Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector<Point3f> can be also passed here. |
| imagePoints | Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points. vector<Point2f> can be also passed here. |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{fx}{0}{cx}{0}{fy}{cy}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvec | Output rotation vector (see Rodrigues ) that, together with tvec, brings points from the model coordinate system to the camera coordinate system. |
| tvec | Output translation vector. |
| useExtrinsicGuess | Parameter used for SOLVEPNP_ITERATIVE. If true (1), the function uses the provided rvec and tvec values as initial approximations of the rotation and translation vectors, respectively, and further optimizes them. |
| iterationsCount | Number of iterations. |
| reprojectionError | Inlier threshold value used by the RANSAC procedure. The parameter value is the maximum allowed distance between the observed and computed point projections to consider it an inlier. |
| confidence | The probability that the algorithm produces a useful result. |
| inliers | Output vector that contains indices of inliers in objectPoints and imagePoints . |
| flags | Method for solving a PnP problem (see solvePnP ). |
The function estimates an object pose given a set of object points, their corresponding image projections, as well as the camera matrix and the distortion coefficients. This function finds such a pose that minimizes reprojection error, that is, the sum of squared distances between the observed projections imagePoints and the projected (using projectPoints ) objectPoints. The use of RANSAC makes the function resistant to outliers.
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::solvePnPRefineLM | ( | InputArray | objectPoints, |
| InputArray | imagePoints, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| InputOutputArray | rvec, | ||
| InputOutputArray | tvec, | ||
| TermCriteria | criteria = TermCriteria(TermCriteria::EPS+TermCriteria::COUNT, 20, FLT_EPSILON) |
||
| ) |
#include <opencv2/calib3d.hpp>
Refine a pose (the translation and the rotation that transform a 3D point expressed in the object coordinate frame to the camera coordinate frame) from a 3D-2D point correspondences and starting from an initial solution.
| objectPoints | Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector<Point3f> can also be passed here. |
| imagePoints | Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points. vector<Point2f> can also be passed here. |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{fx}{0}{cx}{0}{fy}{cy}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvec | Input/Output rotation vector (see Rodrigues ) that, together with tvec, brings points from the model coordinate system to the camera coordinate system. Input values are used as an initial solution. |
| tvec | Input/Output translation vector. Input values are used as an initial solution. |
| criteria | Criteria when to stop the Levenberg-Marquard iterative algorithm. |
The function refines the object pose given at least 3 object points, their corresponding image projections, an initial solution for the rotation and translation vector, as well as the camera matrix and the distortion coefficients. The function minimizes the projection error with respect to the rotation and the translation vectors, according to a Levenberg-Marquardt iterative minimization [60] [27] process.
Referenced by cv::LMSolver::Callback::~Callback().

| void cv::solvePnPRefineVVS | ( | InputArray | objectPoints, |
| InputArray | imagePoints, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| InputOutputArray | rvec, | ||
| InputOutputArray | tvec, | ||
| TermCriteria | criteria = TermCriteria(TermCriteria::EPS+TermCriteria::COUNT, 20, FLT_EPSILON), |
||
| double | VVSlambda = 1 |
||
| ) |
#include <opencv2/calib3d.hpp>
Refine a pose (the translation and the rotation that transform a 3D point expressed in the object coordinate frame to the camera coordinate frame) from a 3D-2D point correspondences and starting from an initial solution.
| objectPoints | Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector<Point3f> can also be passed here. |
| imagePoints | Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points. vector<Point2f> can also be passed here. |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{fx}{0}{cx}{0}{fy}{cy}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvec | Input/Output rotation vector (see Rodrigues ) that, together with tvec, brings points from the model coordinate system to the camera coordinate system. Input values are used as an initial solution. |
| tvec | Input/Output translation vector. Input values are used as an initial solution. |
| criteria | Criteria when to stop the Levenberg-Marquard iterative algorithm. |
| VVSlambda | Gain for the virtual visual servoing control law, equivalent to the \(\alpha\) gain in the Damped Gauss-Newton formulation. |
The function refines the object pose given at least 3 object points, their corresponding image projections, an initial solution for the rotation and translation vector, as well as the camera matrix and the distortion coefficients. The function minimizes the projection error with respect to the rotation and the translation vectors, using a virtual visual servoing (VVS) [20] [64] scheme.
Referenced by cv::LMSolver::Callback::~Callback().

| double cv::stereoCalibrate | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints1, | ||
| InputArrayOfArrays | imagePoints2, | ||
| InputOutputArray | cameraMatrix1, | ||
| InputOutputArray | distCoeffs1, | ||
| InputOutputArray | cameraMatrix2, | ||
| InputOutputArray | distCoeffs2, | ||
| Size | imageSize, | ||
| InputOutputArray | R, | ||
| InputOutputArray | T, | ||
| OutputArray | E, | ||
| OutputArray | F, | ||
| OutputArray | perViewErrors, | ||
| int | flags = CALIB_FIX_INTRINSIC, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, 1e-6) |
||
| ) |
#include <opencv2/calib3d.hpp>
Calibrates the stereo camera.
| objectPoints | Vector of vectors of the calibration pattern points. |
| imagePoints1 | Vector of vectors of the projections of the calibration pattern points, observed by the first camera. |
| imagePoints2 | Vector of vectors of the projections of the calibration pattern points, observed by the second camera. |
| cameraMatrix1 | Input/output first camera matrix: \(\vecthreethree{f_x^{(j)}}{0}{c_x^{(j)}}{0}{f_y^{(j)}}{c_y^{(j)}}{0}{0}{1}\) , \(j = 0,\, 1\) . If any of CALIB_USE_INTRINSIC_GUESS , CALIB_FIX_ASPECT_RATIO , CALIB_FIX_INTRINSIC , or CALIB_FIX_FOCAL_LENGTH are specified, some or all of the matrix components must be initialized. See the flags description for details. |
| distCoeffs1 | Input/output vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6 [, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. The output vector length depends on the flags. |
| cameraMatrix2 | Input/output second camera matrix. The parameter is similar to cameraMatrix1 |
| distCoeffs2 | Input/output lens distortion coefficients for the second camera. The parameter is similar to distCoeffs1 . |
| imageSize | Size of the image used only to initialize intrinsic camera matrix. |
| R | Output rotation matrix between the 1st and the 2nd camera coordinate systems. |
| T | Output translation vector between the coordinate systems of the cameras. |
| E | Output essential matrix. |
| F | Output fundamental matrix. |
| perViewErrors | Output vector of the RMS re-projection error estimated for each pattern view. |
| flags | Different flags that may be zero or a combination of the following values:
|
| criteria | Termination criteria for the iterative optimization algorithm. |
The function estimates transformation between two cameras making a stereo pair. If you have a stereo camera where the relative position and orientation of two cameras is fixed, and if you computed poses of an object relative to the first camera and to the second camera, (R1, T1) and (R2, T2), respectively (this can be done with solvePnP ), then those poses definitely relate to each other. This means that, given ( \(R_1\), \(T_1\) ), it should be possible to compute ( \(R_2\), \(T_2\) ). You only need to know the position and orientation of the second camera relative to the first camera. This is what the described function does. It computes ( \(R\), \(T\) ) so that:
\[R_2=R*R_1\]
\[T_2=R*T_1 + T,\]
Optionally, it computes the essential matrix E:
\[E= \vecthreethree{0}{-T_2}{T_1}{T_2}{0}{-T_0}{-T_1}{T_0}{0} *R\]
where \(T_i\) are components of the translation vector \(T\) : \(T=[T_0, T_1, T_2]^T\) . And the function can also compute the fundamental matrix F:
\[F = cameraMatrix2^{-T} E cameraMatrix1^{-1}\]
Besides the stereo-related information, the function can also perform a full calibration of each of two cameras. However, due to the high dimensionality of the parameter space and noise in the input data, the function can diverge from the correct solution. If the intrinsic parameters can be estimated with high accuracy for each of the cameras individually (for example, using calibrateCamera ), you are recommended to do so and then pass CALIB_FIX_INTRINSIC flag to the function along with the computed intrinsic parameters. Otherwise, if all the parameters are estimated at once, it makes sense to restrict some parameters, for example, pass CALIB_SAME_FOCAL_LENGTH and CALIB_ZERO_TANGENT_DIST flags, which is usually a reasonable assumption.
Similarly to calibrateCamera , the function minimizes the total re-projection error for all the points in all the available views from both cameras. The function returns the final value of the re-projection error.
| double cv::stereoCalibrate | ( | InputArrayOfArrays | objectPoints, |
| InputArrayOfArrays | imagePoints1, | ||
| InputArrayOfArrays | imagePoints2, | ||
| InputOutputArray | cameraMatrix1, | ||
| InputOutputArray | distCoeffs1, | ||
| InputOutputArray | cameraMatrix2, | ||
| InputOutputArray | distCoeffs2, | ||
| Size | imageSize, | ||
| OutputArray | R, | ||
| OutputArray | T, | ||
| OutputArray | E, | ||
| OutputArray | F, | ||
| int | flags = CALIB_FIX_INTRINSIC, |
||
| TermCriteria | criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, 1e-6) |
||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| void cv::stereoRectify | ( | InputArray | cameraMatrix1, |
| InputArray | distCoeffs1, | ||
| InputArray | cameraMatrix2, | ||
| InputArray | distCoeffs2, | ||
| Size | imageSize, | ||
| InputArray | R, | ||
| InputArray | T, | ||
| OutputArray | R1, | ||
| OutputArray | R2, | ||
| OutputArray | P1, | ||
| OutputArray | P2, | ||
| OutputArray | Q, | ||
| int | flags = CALIB_ZERO_DISPARITY, |
||
| double | alpha = -1, |
||
| Size | newImageSize = Size(), |
||
| Rect * | validPixROI1 = 0, |
||
| Rect * | validPixROI2 = 0 |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes rectification transforms for each head of a calibrated stereo camera.
| cameraMatrix1 | First camera matrix. |
| distCoeffs1 | First camera distortion parameters. |
| cameraMatrix2 | Second camera matrix. |
| distCoeffs2 | Second camera distortion parameters. |
| imageSize | Size of the image used for stereo calibration. |
| R | Rotation matrix between the coordinate systems of the first and the second cameras. |
| T | Translation vector between coordinate systems of the cameras. |
| R1 | Output 3x3 rectification transform (rotation matrix) for the first camera. |
| R2 | Output 3x3 rectification transform (rotation matrix) for the second camera. |
| P1 | Output 3x4 projection matrix in the new (rectified) coordinate systems for the first camera. |
| P2 | Output 3x4 projection matrix in the new (rectified) coordinate systems for the second camera. |
| Q | Output \(4 \times 4\) disparity-to-depth mapping matrix (see reprojectImageTo3D ). |
| flags | Operation flags that may be zero or CALIB_ZERO_DISPARITY . If the flag is set, the function makes the principal points of each camera have the same pixel coordinates in the rectified views. And if the flag is not set, the function may still shift the images in the horizontal or vertical direction (depending on the orientation of epipolar lines) to maximize the useful image area. |
| alpha | Free scaling parameter. If it is -1 or absent, the function performs the default scaling. Otherwise, the parameter should be between 0 and 1. alpha=0 means that the rectified images are zoomed and shifted so that only valid pixels are visible (no black areas after rectification). alpha=1 means that the rectified image is decimated and shifted so that all the pixels from the original images from the cameras are retained in the rectified images (no source image pixels are lost). Obviously, any intermediate value yields an intermediate result between those two extreme cases. |
| newImageSize | New image resolution after rectification. The same size should be passed to initUndistortRectifyMap (see the stereo_calib.cpp sample in OpenCV samples directory). When (0,0) is passed (default), it is set to the original imageSize . Setting it to larger value can help you preserve details in the original image, especially when there is a big radial distortion. |
| validPixROI1 | Optional output rectangles inside the rectified images where all the pixels are valid. If alpha=0 , the ROIs cover the whole images. Otherwise, they are likely to be smaller (see the picture below). |
| validPixROI2 | Optional output rectangles inside the rectified images where all the pixels are valid. If alpha=0 , the ROIs cover the whole images. Otherwise, they are likely to be smaller (see the picture below). |
The function computes the rotation matrices for each camera that (virtually) make both camera image planes the same plane. Consequently, this makes all the epipolar lines parallel and thus simplifies the dense stereo correspondence problem. The function takes the matrices computed by stereoCalibrate as input. As output, it provides two rotation matrices and also two projection matrices in the new coordinates. The function distinguishes the following two cases:
Horizontal stereo: the first and the second camera views are shifted relative to each other mainly along the x axis (with possible small vertical shift). In the rectified images, the corresponding epipolar lines in the left and right cameras are horizontal and have the same y-coordinate. P1 and P2 look like:
\[\texttt{P1} = \begin{bmatrix} f & 0 & cx_1 & 0 \\ 0 & f & cy & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix}\]
\[\texttt{P2} = \begin{bmatrix} f & 0 & cx_2 & T_x*f \\ 0 & f & cy & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} ,\]
where \(T_x\) is a horizontal shift between the cameras and \(cx_1=cx_2\) if CALIB_ZERO_DISPARITY is set.
Vertical stereo: the first and the second camera views are shifted relative to each other mainly in vertical direction (and probably a bit in the horizontal direction too). The epipolar lines in the rectified images are vertical and have the same x-coordinate. P1 and P2 look like:
\[\texttt{P1} = \begin{bmatrix} f & 0 & cx & 0 \\ 0 & f & cy_1 & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix}\]
\[\texttt{P2} = \begin{bmatrix} f & 0 & cx & 0 \\ 0 & f & cy_2 & T_y*f \\ 0 & 0 & 1 & 0 \end{bmatrix} ,\]
where \(T_y\) is a vertical shift between the cameras and \(cy_1=cy_2\) if CALIB_ZERO_DISPARITY is set.
As you can see, the first three columns of P1 and P2 will effectively be the new "rectified" camera matrices. The matrices, together with R1 and R2 , can then be passed to initUndistortRectifyMap to initialize the rectification map for each camera.
See below the screenshot from the stereo_calib.cpp sample. Some red horizontal lines pass through the corresponding image regions. This means that the images are well rectified, which is what most stereo correspondence algorithms rely on. The green rectangles are roi1 and roi2 . You see that their interiors are all valid pixels.

| bool cv::stereoRectifyUncalibrated | ( | InputArray | points1, |
| InputArray | points2, | ||
| InputArray | F, | ||
| Size | imgSize, | ||
| OutputArray | H1, | ||
| OutputArray | H2, | ||
| double | threshold = 5 |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes a rectification transform for an uncalibrated stereo camera.
| points1 | Array of feature points in the first image. |
| points2 | The corresponding points in the second image. The same formats as in findFundamentalMat are supported. |
| F | Input fundamental matrix. It can be computed from the same set of point pairs using findFundamentalMat . |
| imgSize | Size of the image. |
| H1 | Output rectification homography matrix for the first image. |
| H2 | Output rectification homography matrix for the second image. |
| threshold | Optional threshold used to filter out the outliers. If the parameter is greater than zero, all the point pairs that do not comply with the epipolar geometry (that is, the points for which \(|\texttt{points2[i]}^T*\texttt{F}*\texttt{points1[i]}|>\texttt{threshold}\) ) are rejected prior to computing the homographies. Otherwise, all the points are considered inliers. |
The function computes the rectification transformations without knowing intrinsic parameters of the cameras and their relative position in the space, which explains the suffix "uncalibrated". Another related difference from stereoRectify is that the function outputs not the rectification transformations in the object (3D) space, but the planar perspective transformations encoded by the homography matrices H1 and H2 . The function implements the algorithm [41] .
| void cv::triangulatePoints | ( | InputArray | projMatr1, |
| InputArray | projMatr2, | ||
| InputArray | projPoints1, | ||
| InputArray | projPoints2, | ||
| OutputArray | points4D | ||
| ) |
#include <opencv2/calib3d.hpp>
Reconstructs points by triangulation.
| projMatr1 | 3x4 projection matrix of the first camera. |
| projMatr2 | 3x4 projection matrix of the second camera. |
| projPoints1 | 2xN array of feature points in the first image. In case of c++ version it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1. |
| projPoints2 | 2xN array of corresponding points in the second image. In case of c++ version it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1. |
| points4D | 4xN array of reconstructed points in homogeneous coordinates. |
The function reconstructs 3-dimensional points (in homogeneous coordinates) by using their observations with a stereo camera. Projections matrices can be obtained from stereoRectify.
| void cv::undistort | ( | InputArray | src, |
| OutputArray | dst, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| InputArray | newCameraMatrix = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Transforms an image to compensate for lens distortion.
The function transforms an image to compensate radial and tangential lens distortion.
The function is simply a combination of initUndistortRectifyMap (with unity R ) and remap (with bilinear interpolation). See the former function for details of the transformation being performed.
Those pixels in the destination image, for which there is no correspondent pixels in the source image, are filled with zeros (black color).
A particular subset of the source image that will be visible in the corrected image can be regulated by newCameraMatrix. You can use getOptimalNewCameraMatrix to compute the appropriate newCameraMatrix depending on your requirements.
The camera matrix and the distortion parameters can be determined using calibrateCamera. If the resolution of images is different from the resolution used at the calibration stage, \(f_x, f_y, c_x\) and \(c_y\) need to be scaled accordingly, while the distortion coefficients remain the same.
| src | Input (distorted) image. |
| dst | Output (corrected) image that has the same size and type as src . |
| cameraMatrix | Input camera matrix \(A = \vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6[, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| newCameraMatrix | Camera matrix of the distorted image. By default, it is the same as cameraMatrix but you may additionally scale and shift the result by using a different matrix. |
| void cv::undistortPoints | ( | InputArray | src, |
| OutputArray | dst, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| InputArray | R = noArray(), |
||
| InputArray | P = noArray() |
||
| ) |
#include <opencv2/calib3d.hpp>
Computes the ideal point coordinates from the observed point coordinates.
The function is similar to undistort and initUndistortRectifyMap but it operates on a sparse set of points instead of a raster image. Also the function performs a reverse transformation to projectPoints. In case of a 3D object, it does not reconstruct its 3D coordinates, but for a planar object, it does, up to a translation vector, if the proper R is specified.
For each observed point coordinate \((u, v)\) the function computes:
\[ \begin{array}{l} x^{"} \leftarrow (u - c_x)/f_x \\ y^{"} \leftarrow (v - c_y)/f_y \\ (x',y') = undistort(x^{"},y^{"}, \texttt{distCoeffs}) \\ {[X\,Y\,W]} ^T \leftarrow R*[x' \, y' \, 1]^T \\ x \leftarrow X/W \\ y \leftarrow Y/W \\ \text{only performed if P is specified:} \\ u' \leftarrow x {f'}_x + {c'}_x \\ v' \leftarrow y {f'}_y + {c'}_y \end{array} \]
where undistort is an approximate iterative algorithm that estimates the normalized original point coordinates out of the normalized distorted point coordinates ("normalized" means that the coordinates do not depend on the camera matrix).
The function can be used for both a stereo camera head or a monocular camera (when R is empty).
| src | Observed point coordinates, 2xN/Nx2 1-channel or 1xN/Nx1 2-channel (CV_32FC2 or CV_64FC2) (or vector<Point2f> ). |
| dst | Output ideal point coordinates (1xN/Nx1 2-channel or vector<Point2f> ) after undistortion and reverse perspective transformation. If matrix P is identity or omitted, dst will contain normalized point coordinates. |
| cameraMatrix | Camera matrix \(\vecthreethree{f_x}{0}{c_x}{0}{f_y}{c_y}{0}{0}{1}\) . |
| distCoeffs | Input vector of distortion coefficients \((k_1, k_2, p_1, p_2[, k_3[, k_4, k_5, k_6[, s_1, s_2, s_3, s_4[, \tau_x, \tau_y]]]])\) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| R | Rectification transformation in the object space (3x3 matrix). R1 or R2 computed by stereoRectify can be passed here. If the matrix is empty, the identity transformation is used. |
| P | New camera matrix (3x3) or new projection matrix (3x4) \(\begin{bmatrix} {f'}_x & 0 & {c'}_x & t_x \\ 0 & {f'}_y & {c'}_y & t_y \\ 0 & 0 & 1 & t_z \end{bmatrix}\). P1 or P2 computed by stereoRectify can be passed here. If the matrix is empty, the identity new camera matrix is used. |
Referenced by cv::initWideAngleProjMap().

| void cv::undistortPoints | ( | InputArray | src, |
| OutputArray | dst, | ||
| InputArray | cameraMatrix, | ||
| InputArray | distCoeffs, | ||
| InputArray | R, | ||
| InputArray | P, | ||
| TermCriteria | criteria | ||
| ) |
#include <opencv2/calib3d.hpp>
This is an overloaded member function, provided for convenience. It differs from the above function only in what argument(s) it accepts.
| void cv::validateDisparity | ( | InputOutputArray | disparity, |
| InputArray | cost, | ||
| int | minDisparity, | ||
| int | numberOfDisparities, | ||
| int | disp12MaxDisp = 1 |
||
| ) |
#include <opencv2/calib3d.hpp>
validates disparity using the left-right check. The matrix "cost" should be computed by the stereo correspondence algorithm
 1.8.13
1.8.13